
“Recommended for You”
YouTube, Amazon, Netflix, X, news sites… We are surrounded by services displaying recommendations. While convenient, have you ever felt, “I keep getting recommended the same kinds of things,” or “I wish I could get recommendations from a different perspective”? Or perhaps wondered, “Are these recommendations biased?”
The truth is, these “recommendations” (recommender systems) are typically generated on the service provider’s servers, based on data and algorithms hidden from us users. Users have generally had no choice but to accept the recommendations presented.
But what if users themselves could create their own “fair” and “transparent” recommender systems, without relying on the service provider’s secret data?
“That’s impossible!” you might think.
However, a new technological trend that might make this possible, “user-side recommender systems,” has emerged, along with proposed theoretical underpinnings and practical methods.
Why Do We Need “My Own Recommendations”? Challenges of Traditional Recommender Systems
First, why would users want to build their own recommender systems? Traditional systems created by service providers (server-side recommender systems) have several issues:
- Black-Box Nature: It’s often unclear why something was recommended.
- Lack of Control: Users usually find it difficult to freely change or adjust the recommendation content.
- Fairness Issues and Filter Bubbles: There’s a risk of creating “filter bubbles” where users only see what they already like, narrowing their perspectives, or receiving recommendations biased towards specific attributes (like gender, race, popularity, etc.). For example, a user identifying as a Republican supporter, despite wanting to Democrat read news, is shown only Republican-related news to maximize click-through rates.
“User-side recommender systems” offer a groundbreaking solution to these challenges.
The New Wave: User-Side Recommender Systems
User-side recommender systems are, literally, recommender systems built and run on the “user side”.
- Who builds them? The users themselves (or third-party tools assisting users).
- Where do they run? On the user’s environment, such as their PC, smartphone, or browser extensions.
- What are the benefits?
- Transparency: Since users build them (or can see inside), it’s easier to understand why something is recommended.
- Controllability: Users can freely adjust recommendation criteria based on their own values (e.g., “I want to see more diverse opinions,” “I want to discover lesser-known works”).
- Fairness: Even if the service’s recommendations are biased, users can create recommendation lists that meet their own defined fairness criteria (e.g., gender ratio, old/new ratio).
- Privacy: Potentially avoids providing large amounts of personal data to the service provider.
However, users do not have direct access to the database storing user logs and item information that companies possess. Isn’t it impossible to create effective recommender systems without such data?
Exactly. This was the biggest hurdle for user-side recommender systems. However, prior research by Sato and others introduced the idea of “reverse-using the ‘existing recommendation information’ provided by the service.” In other words, even without access to the company’s database, information displayed on web pages like “Customers who bought this item also bought…” can be used as “material”.
However, this approach was largely empirical, leaving questions like, “Does this really provide enough information?” and “Is there theoretical backing?”
“Hidden Features” Can Be Recovered from Recommendation Information
Surprisingly, it has been shown that it might be theoretically possible to recover the underlying “hidden features (embedding)” of items using only the information from “recommendation lists” displayed on web pages.
Many recommender systems internally represent each item as a numerical vector (called a feature vector or embedding) and recommend items whose vectors are similar (close in distance). These vectors themselves are typically created from company-secret data (purchase history, rating logs, etc.) and are invisible externally.
We focus on “recommendation network” (also called a k-NN graph) formed by connecting items as nodes and recommendation relationships (item B is included in item A’s recommendations) as edges. This network structure is observable by users (by following web pages).
Using theories developed in graph theory and machine learning, specifically “Metric Recovery,” it’s suggested that from only the information in this recommendation network (how nodes and edges connect), one can estimate the original “distances” between items and even reconstruct the “arrangement” of items in the original vector space (excluding rotation, scaling, etc.)
Look at the figure below.
(a) Confidential Features (Not Public): The item features that normally only the service provider has (in this example, people’s age and capital gain).
(b) Recommendation Network (Public Information): The “recommendation” relationships observable by users from web pages.
(c) Recovered Features: The item features theoretically recovered using only the recommendation network from (b).
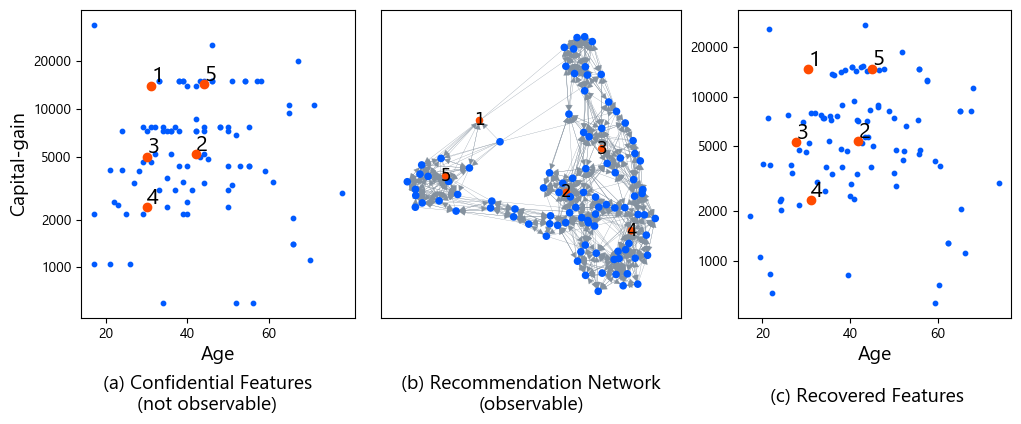
We see how the original features in (a) and the recovered features in (c) have almost the same structure. This indicates the possibility of reconstructing the “heart” of the recommender system using only information visible to users.
Two Shocks Delivered by This Theory:
- User-Side Recommender Systems Are Theoretically Possible! The necessary information was actually within the user’s reach.
- New Privacy/Security Concerns. If a recommender system uses sensitive personal information (e.g., education level, income) to make recommendations, this implies a risk that such information could be unintentionally recovered externally. Service providers need to address this information leakage risk.
Theory Isn’t Enough? 3 Hurdles and Design Principles for Practicality
The theory that allows feature recovery (ETP: Estimate-then-Postprocessing approach) is a attractive discovery, but it has a major practical problem:
It’s incredibly inefficient.
To accurately recover features using this theory, you need to collect recommendation information for almost all items from the website. For services with a vast number of items, this is unrealistic, i.e., communication costs and time are prohibitive.
So, are user-side recommender systems just a pipe dream after all?
No, don’t give up yet. We propose not aiming for “perfect feature recovery,” but instead define “Three Desirable Properties (Design Principles)” that practical user-side recommender systems should meet:
- Consistency: If the user doesn’t specifically demand fairness (\(\tau=0\)), the system should produce recommendations as good as (high accuracy) the original service. It shouldn’t arbitrarily degrade performance.
- Soundness: If the user specifies “recommend at least \(\tau\) items from each group,” the system should be able to guarantee this requirement. It must ensure fairness reliably, not just “try” to be fair.
- Locality: The number of website accesses required to generate recommendations should not be linear but a constant. It shouldn’t need to collect info on all items; it should be able to produce recommendations quickly with low communication cost.
When existing user-side recommendation methods (like PRIVATERANK or PRIVATEWALK) are evaluated against these principles, unfortunately, none satisfy all three.
| PP | PrivateRank | PrivateWalk | ETP | CONSUL | |
|---|---|---|---|---|---|
| Consistent | ✓ | ✓ | ✗ | ✓ | ✓ |
| Sound | ✗ | ✓ | ✓ | ✓ | ✓ |
| Local | ✓ | ✗ | ✓ | ✗ | ✓ |
CONSUL – An Efficient New Method Meeting the 3 Principles
This is where CONSUL (CONsistent, SoUnd, and Local), a new algorithm, comes in! As its name suggests, it’s designed to satisfy all three principles (Consistency, Soundness, Locality).
CONSUL cleverly uses information observable by the user – namely, the results (output) of the existing official recommender system – to efficiently explore the recommendation network, without accessing the service provider’s internal data (like full user logs or item feature databases).
The algorithm aims to construct a recommendation list \(R\) of \(K\) items that satisfies the specified fairness constraints (recommend at least \(\tau\) items from each attribute group) while considering relevance to the original system (Consistency) and using limited web access (Locality).
A user running CONSUL is assumed to have access to the following information:
- Oracle Access to the Official Recommendation System (\(P_{prov}\)): A function where giving any item \(i\) as input returns the \(K\) recommended items \(P_{prov}(i)\) generated by the service provider’s official system. This corresponds to visiting a specific item page on a website and viewing the “related items” or “recommendations” list. The user doesn’t need to know the internal logic of \(P_{prov}\) or the data it’s based on.
- Item Sensitive Attributes (\(a_i\)): Information about the attribute group (e.g., genre, release year, gender) to which each item \(i\) belongs. This needs to be collected beforehand, assigned, or perhaps estimated separately, but the algorithm itself uses this information as input.
- User Interaction History (\(H\)): The set of items the user has already interacted with (e.g., purchased, watched). This is used to exclude items from recommendations.
Exploration Process:
The goal is to generate a recommendation list for the seed item, i.e., the item the user is currently viewing.
The algorithm performs a walk-based search similar to Depth-First Search (DFS), starting from the seed item, to build the recommendation list \(R\) of \(K\) items.
- Candidate Retrieval and Evaluation: Get the official recommendation list \(P_{prov}(p)\) for the currently focused item \(p\). Evaluate each item \(j\) in this list as a recommendation candidate.
- Check Additional Conditions: Determine if candidate \(j\) meets the following criteria:
- Has not been recommended yet and is not in the user’s history \(H\).
- Fairness Satisfiability Check: This is a crucial step guaranteeing CONSUL’s Soundness. It verifies if adding \(j\) to list \(R\) still allows the target fairness (at least \(\tau\) items from each attribute group) to be potentially met within the remaining empty slots. Specifically, it mathematically checks if the shortfall for other attribute groups after adding \(j\) can be covered by the number of remaining empty slots.
- Add to List and Next Exploration: If \(j\) meets the conditions, add it to list \(R\) and update relevant counters. The next item to explore is selected DFS-style from the current recommendation list \(P_{prov}(p)\) and managed using a stack.
- Termination Condition: This exploration process continues until list \(R\) is filled with \(K\) items or a preset maximum number of exploration steps \(L_{max}\) is reached.
Why is it Executable by Users?
The rationale for CONSUL being executable user-side lies in its inputs and operations being limited to what a user can access:
- Limited Oracle Access: The only request the algorithm makes to the service provider is “give me the recommendation list \(P_{prov}(p)\) for item \(p\)” (Line 12 in the algorithm). This is essentially the same as a user opening a product page in a browser and looking at the “related products” list. Access to internal recommendation logic, overall user log data, or item similarity scores is completely unnecessary.
- Attribute Info and History: Item attributes \(a_i\) and user history \(H\) are assumed to be information the user can hold or acquire. Even if attribute information isn’t directly available, estimates for \(a_i\) can be obtained using basic machine learning models like neural networks or random forests.
- Computation Location: The algorithm’s exploration logic (stack operations, condition checks, list management, etc.) all runs on the user’s device (PC, smartphone, browser extension, etc.). No special server-side processing is required.
While proofs are omitted here, CONSUL can be shown to possess Consistency, Soundness, and Locality. Moreover, the computation time required does not depend on the total number of items, and the communication cost (number of website accesses) is drastically reduced compared to existing methods.
Does CONSUL Really Work? Experimental Results
Theory and design are great, but they’re meaningless if not practically usable. We validate CONSUL’s capabilities through various experiments.
(1) Is Feature Recovery Really Possible? (RQ1)
This corresponds to the Figure 1 experiment mentioned earlier. Using the Adult dataset, it demonstrated that original features (age, capital gain) could be recovered with high accuracy solely from recommendation results (the recommendation network). This shows the solid theoretical foundation of user-side recommender systems.
(2) How are CONSUL’s Performance and Efficiency? (RQ2)
Comparisons were made with other methods on various datasets (Adult, MovieLens, Amazon, LastFM).
| Method | Dataset | Performance Metric (e.g., nDCG↑) | Comm. Cost (Accesses↓) |
|---|---|---|---|
| Oracle (Ideal) | MovieLens(old) | 0.057 | 0 |
| PRIVATERANK | MovieLens(old) | 0.055 | 1682 |
| PRIVATEWALK | MovieLens(old) | 0.027 (Perf. Drop) | 154.2 |
| CONSUL | MovieLens(old) | 0.057 (High Perf.) | 19.6 (Ultra Low Cost) |
| Oracle (Ideal) | Amazon | 0.057 | 0 |
| PRIVATERANK | Amazon | 0.057 | 1171 |
| PRIVATEWALK | Amazon | 0.048 (Perf. Drop) | 135.7 |
| CONSUL | Amazon | 0.052 (High Perf.) | 7.3 (Ultra Low Cost) |
The results were interesting.
- Overwhelming Efficiency: CONSUL generated recommendations with over 10 times less communication cost (accesses) compared even to PRIVATEWALK! Especially on Amazon and LastFM, it only needed 6-7 accesses. This level is sufficiently feasible for real-time recommendation generation.
- High Performance: Despite being so efficient, its recommendation quality (nDCG or Recall) rivaled the ideal Oracle and the very costly PRIVATERANK. This contrasts with PRIVATEWALK, which sacrificed performance for efficiency.
CONSUL demonstrated an astonishingly superior balance in the performance-efficiency trade-off.
(3) How Do Users Evaluate CONSUL? Any New Discoveries? (RQ3)
Actual users evaluated it via crowdsourcing. Using the MovieLens dataset, they compared the original recommendations (Provider) with CONSUL’s recommendation lists. Fairness was defined as balancing recommendations between older and newer movies based on release year (\(\tau=3\)).
Results
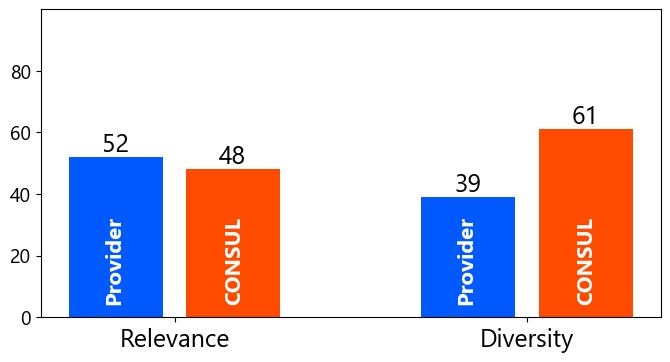
- Relevance: CONSUL was rated as having relevance comparable to, or slightly less than, the original recommendations (interestingness, appropriateness).
- Diversity: On the other hand, CONSUL was clearly rated higher in terms of diversity (spread of release years)!
In essence, CONSUL successfully improved the diversity (fairness) users desired, without significantly compromising the quality of the original recommendations.
| Provider | CONSUL |
|---|---|
| Total Recall (1990) | Total Recall (1990) |
| The Matrix (1990) | The Matrix (1990) |
| The Terminator (1990) | The Terminator (1990) |
| Jurassic Park (1993) | Alien (1979) |
| Men in Black (1997) | Star Wars: Episode IV (1977) |
| The Fugitive (1993) | Star Trek: The Motion Picture (1979) |
Even more surprisingly, CONSUL could discover items that were overlooked by the original recommendation system. For example, for “Terminator 2 (1991)”, the original recommendations were mostly relatively new sci-fi films, but CONSUL appropriately recommended classic masterpieces like “Alien (1979)” and “Star Wars (1977)”, which was highly rated by users in some cases. User-side recommender systems hold the potential to fill the “gaps” in existing systems.
(4) Can it be used in the Real World? (RQ4)
Finally, a case study applied CONSUL to Twitter’s actual user recommendation system. The key point is that the author is not a Twitter employee, but just an ordinary Twitter user.
| Provider N/A | PrivateWalk (23 accesses) | CONSUL (5 accesses) |
|---|---|---|
| Chris Hemsworth (man) | Ian McKellen (man) | Chris Hemsworth (man) |
| Chris Pratt (man) | Zac Efron (man) | Chris Pratt (man) |
| Ian McKellen (man) | Seth Green (man) | Ian McKellen (man) |
| Zac Efron (man) | Dana Bash (woman) | Brie Larson (woman) |
| Patrick Stewart (man) | Lena Dunham (woman) | Danai Gurira (woman) |
| Seth Rogen (man) | Jena Malone (woman) | Kat Dennings (woman) |
The original recommendations were all men, but CONSUL successfully generated a perfectly gender-balanced (3 men, 3 women) recommendation list with just 5 API accesses! Of course, all recommended users were highly relevant actors. Applying ETP or PRIVATERANK to large-scale services like Twitter is difficult due to prohibitive communication costs. CONSUL’s practicality was proven here as well. As mentioned, the author is just an ordinary Twitter user. The noteworthy point is that a regular user created a new Twitter recommendation system and achieved more desirable results than the official system.
Summary: The Dawn of the “My Own Recommendations” Era?
This article showed us many “surprises” and “possibilities”:
- Surprise 1: The theory exists to recover underlying item features just from the visible “recommendation lists”.
- Surprise 2: If that’s possible, there’s also a risk of sensitive information leakage.
- Surprise 3: Three principles (Consistency, Soundness, Locality) for practical user-side systems were proposed.
- Surprise 4: The new method “CONSUL” satisfies all three principles, achieving astonishing efficiency and high performance.
- Surprise 5: Using CONSUL, users might discover diverse information or quality items buried by existing systems.
- Surprise 6: There’s promise for general users to build their own fair recommendation systems even for real-world services like Twitter.
A powerful tool has emerged for “improving our information environment with our own hands.” If you’re dissatisfied with the recommendations on services you use daily, the day might come when you can use technology like CONSUL to customize your own perfect recommender system.
Of course, challenges still exist. These include the privacy issues suggested by the possibility of feature recovery and handling more complex definitions of fairness. However, the trend of “user-side recommender systems,” enabling users to more actively encounter information valuable to them, will undoubtedly become increasingly important.
Doesn’t it make you want to try building your own recommendation system?
Paper: Towards Principled User-side Recommender Systems
GitHub: joisino/consul
Author Profile
If you found this article useful or interesting, I would be delighted if you could share your thoughts on social media.
New posts are announced on @joisino_en (Twitter), so please be sure to follow!

Ryoma Sato
Currently an Assistant Professor at the National Institute of Informatics, Japan.
Research Interest: Machine Learning and Data Mining.
Ph.D (Kyoto University).

