
Model collapse is the phenomenon in which text or images output by AI are uploaded to the internet, those outputs become mixed into AI training data, the AI trained on that data then produces further outputs that are uploaded, and this cycle repeats until AI performance collapses. The most famous study is probably AI models collapse when trained on recursively generated data, which was accepted by Nature [Shumailov+ Nature 2024]. Will Large-scale Generative Models Corrupt Future Datasets? by Hataya et al. is also well known [Hataya+ ICCV 2023]. In this article, I will explain this phenomenon in detail from a variety of angles.
AI-generated content is flooding the web
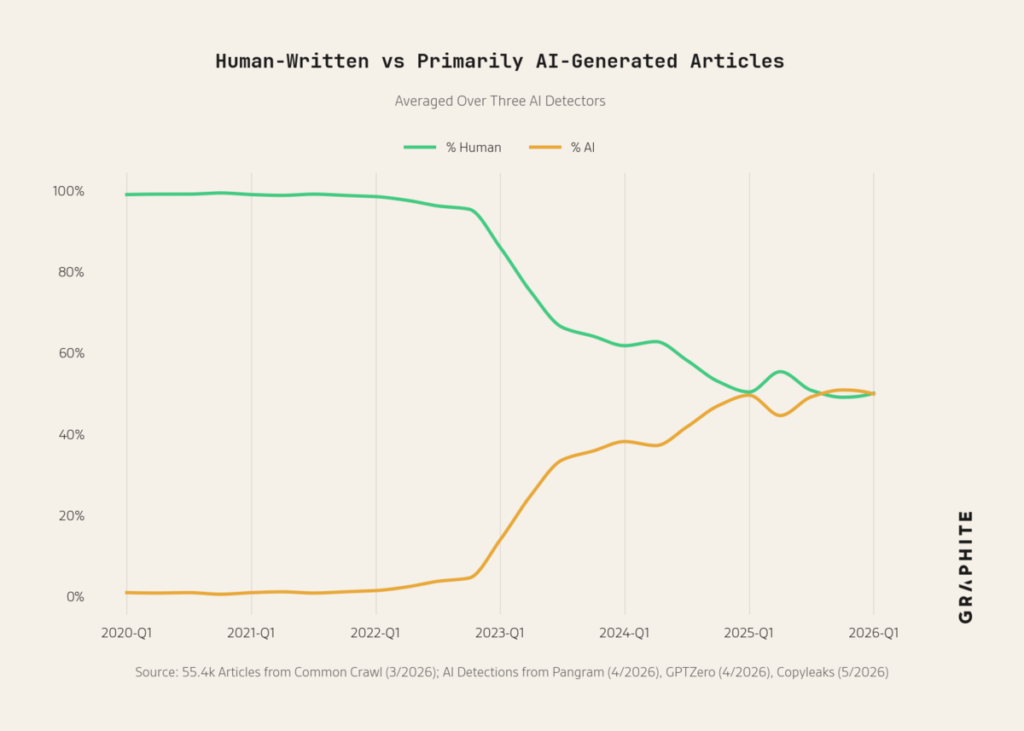
According to a well-known estimate by Greg Druck and colleagues, AI-generated content has spread rapidly across the web since the emergence of ChatGPT, and today roughly half of web articles are said to be written by AI. More specifically, they randomly sampled English media articles and blog articles from Common Crawl, a dump of the web, and fed them into a machine learning model that estimates the proportion of each article written by AI versus humans. When more than half of an article was judged to have been written by AI, it was classified as an article “primarily generated by AI.” The fact that the proportion in the figure above appears to converge around 50 percent might look as if AI-written and human-written articles have become indistinguishable, but that is not what is happening. When newly GPT-5-written articles were fed into the classifier, the reported false negative rate was below 2 percent. They also used three different classifiers, and all of them produced almost the same result. This seems to be a reasonably robust estimate. An independent estimate by Ahrefs also estimated that 38.5 percent of articles use AI for 41 percent or more of their content. In other words, although the number varies somewhat depending on the estimation method, it appears that roughly 30 to 50 percent of textual content is now created mainly using AI. In the visual domain as well, there is a report that 25 percent of the top search results on TikTok are AI-generated.
In other words, the web is now flooded with a non-negligible amount of AI-generated content, and we need to think carefully about its effects.
The problems that arise when AI is retrained on AI-generated content can be broadly divided into two categories: (1) quality degradation and (2) loss of diversity. For quality degradation, methods such as filtering and accumulating datasets have been shown to mitigate the problem. However, the loss of diversity is a more fundamental problem, and even today no fundamental solution has been found. Let us look at the mechanism behind it.
The basic mechanism of model collapse
The main cause of model collapse is that information is diluted generation by generation as iterative training is repeated. As the most basic setting, suppose we train a first-generation model on \(N\) pieces of human-created data. The first-generation model then creates \(N\) new pieces of data, and the second generation is trained on those. The second generation creates data, the third generation is trained on that data, and so on in a chain of repeated training.
Assume that the first-generation model is trained well and captures the human data successfully. In other words, assume that all the information contained in the original \(N\) data points is inherited by the first generation. At this point, no information loss has occurred.
However, when the model creates new data, not all data types are necessarily covered. Sometimes two similar pieces of data are generated, and sometimes, by bad luck, a piece of data similar to some original data point may not appear in the next generation’s dataset.
In this setting, once a data type drops out of the dataset, it never comes back. For example, the number of data points similar to an original data point \(i\) may fluctuate across generations like 1 -> 2 -> 4 -> 3 -> 4 -> 1 -> 0 -> 0 -> 0 -> …, but once it becomes zero, the information about that data point is lost and never returns. Each time this happens, dataset diversity is lost. As a result, in theory, the dataset eventually contracts to a single data point.
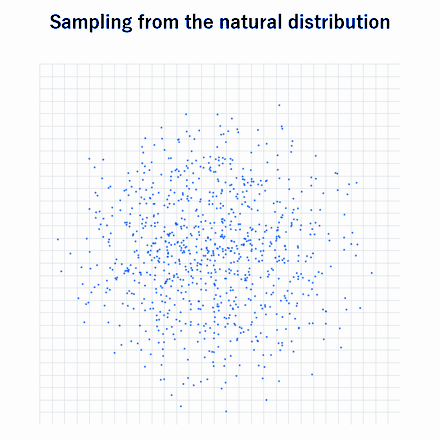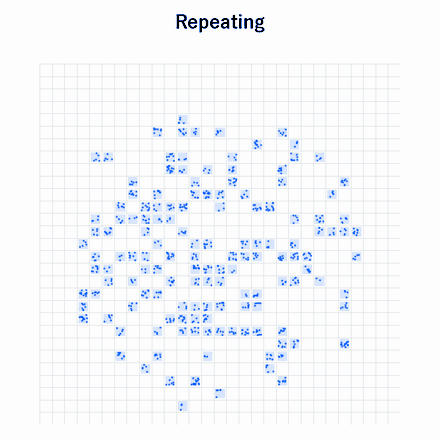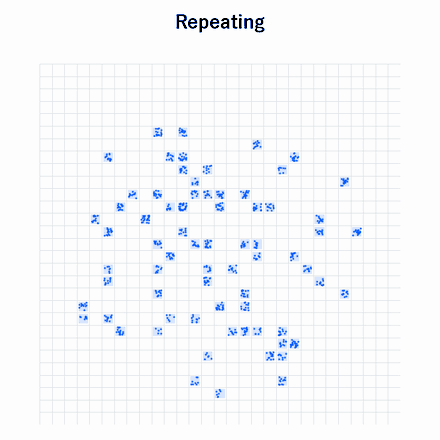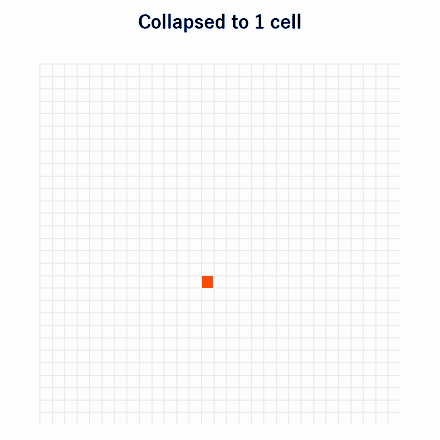
The animation above gives an intuitive illustration of this setting. The data is divided into grid cells. If even one data point enters a cell, the next-generation model is assumed to be able to generate data from that cell well. In the next generation, data is sampled uniformly from all cells that the model can generate. As this process repeats, the number of cells the model can generate gradually decreases, and eventually only one cell remains. This is the basic mechanism by which iterative training reduces diversity.
So far, we have assumed that the model can learn the training data perfectly. Even under such a favorable condition, iterative training can reduce diversity. Worse still, in reality training involves error. This error compounds across generations and can cause quality degradation.

Mitigation: accumulating data
The most basic countermeasure to this problem is to accumulate past data instead of discarding it. After the first-generation model creates \(N\) new pieces of data, the second generation is trained on a total of \(2N\) pieces of data: the original \(N\) data points plus the \(N\) data points created by the first generation. Then the second-generation data is added, and the third generation is trained on \(3N\) data points. On the internet, past data is not immediately deleted; in general, it accumulates. Therefore, the real-world scenario is likely closer to this setting. It has been shown both theoretically and experimentally that accumulating data in this way can suppress model collapse [Gerstgrasser+ COLM 2024]. Intuitively, because the extinction event described in the previous setting does not occur, diversity is preserved. Quality degradation can also be prevented to some extent by retaining the original data. In the previous setting, where new data is sampled every generation, the distribution drifts like a random walk and moves away from the original dataset. In the accumulation setting, by contrast, one can guarantee that the center of mass of the data does not move far from the original position. If you are interested in the theory, please also see the box below.
The \(\frac{\pi^2}{6}\) law: In the theory of suppressing model collapse through data accumulation, the law of \(\frac{\pi^2}{6}\) often appears. In the accumulation setting, the data generated by the \(i\)-th generation model accounts for at most a fraction \(\frac{1}{i+1}\) of the dataset. When using certain losses such as squared error, one can show that the harmful influence of that dataset is at most \(\frac{1}{(i+1)^2}\). Including the “1” from the original dataset, the total influence of all data is at most \(\sum_i \frac{1}{i^2}\), and by the famous Basel problem this is bounded by \(\frac{\pi^2}{6}\). This is only an intuitive explanation, but a structure of this kind is indeed behind the theory. It has been shown for linear models and broader classes of models that even if a model is trained iteratively on model-generated data, training with accumulated data worsens the loss by only a factor of \(\frac{\pi^2}{6} \approx 1.645\) compared with training on the original dataset [Gerstgrasser+ COLM 2024, Dey+ arXiv 2024]. This contrasts with the case where the dataset is replaced every generation, in which the loss deteriorates without bound, and shows that dataset accumulation is theoretically effective as well.
In this way, data accumulation is a realistic and effective method. However, it does not completely solve the problem.
The problem of decoding
The method by which AI generates data, that is, the decoding method, can affect diversity [Taori+ ICML 2022].
As methods for generating text from an autoregressive LLM, there is a method that samples according to the probabilities obtained through training, and there is a method that deterministically generates the token with the highest probability. The latter is called greedy decoding. There are also generation methods such as beam search, which behave somewhere between the two.
For example, suppose we perform next-token prediction for:
She walked along the _____.
There are several possible continuations, such as:
- American English: “sidewalk”
- British English: “pavement”
- Australian English: “footpath”
Suppose that the dataset contains 85 percent American English data like 1, 10 percent British English data like 2, and 5 percent Australian English data like 3.
If a large amount of text is generated by sampling, and if the LLM has captured the characteristics of the dataset well, the generated results will contain about 85 percent American English expressions like 1, about 10 percent British English expressions like 2, and about 5 percent Australian English expressions like 3. There may be some variation, but the diversity of the original data is mostly preserved.
On the other hand, if greedy decoding is used, the result will always be the American English continuation like 1. If such data is added to the training data, American English will become more common in the dataset than it was in the original natural data distribution. If this is repeated, the tendency becomes stronger, and eventually almost 100 percent of the data becomes American English. A model trained on such a dataset will almost certainly generate American English even when sampling is used, and the diversity present in the original natural data distribution will be lost.
In real-world settings, greedy decoding and beam search are often used to improve the quality of responses. Although these methods are not always used, each time they are used, the distribution is distorted away from the natural data distribution, and when those outputs are used as training data, data with minority characteristics becomes increasingly difficult to generate.
Indeed, when you speak casually to ChatGPT in English, it almost always responds in standard American English. If you randomly sampled a conversation partner from all of Japan, much more diverse dialects should appear. In LLM outputs, this kind of natural diversity is lost. Part of this is probably because the web corpus used in the initial training dataset contained a lot of written data in American English in the first place, but decoding and the filtering discussed next are also likely contributing factors.
The problem of filtering
Relatedly, it is common to generate multiple data points and then keep only the high-quality ones, and this can affect diversity. This may be done programmatically, as in best-of-N sampling, or it may be done when a person looks over multiple AI outputs and uploads only the good ones to the internet. As with greedy decoding, each time this happens, the distribution is distorted away from the natural data distribution and diversity is lost. In this way, only the high-quality AI outputs are added to the dataset, and the next generation no longer contains the other data.
One might think that it is fine if AI becomes able to generate only high-quality things. As discussed later, there is some truth to this, but it also contains a problem.
Suppose AI generates one safe 80-point data point and one eccentric 79-point data point. The safe 80-point one is selected. In the first place, it is difficult for an eccentric style to score 80 points or higher, so when a safe style is compared with an eccentric style, the safe style is often selected. Of course, some people prefer eccentric styles. But if we consider the distribution of the internet as a whole, a broadly acceptable, safe style tends to receive more votes, giving safe data a comparative advantage. If this is repeated, even though the original model was capable of generating eccentric but reasonably high-quality data, as training proceeds it becomes unable to generate eccentric data, and essential diversity is lost. Even if the difference is small, extreme repetition can create asymmetry, and many rich styles other than the highest-scoring one may be eliminated.
Even when there are two styles that both score 80 points, a model does not need to learn both in order to achieve a high score on a benchmark. In fact, remembering two equally good styles is not an economical use of memory capacity. As a result of optimization that tries to use memory capacity for other problems, one of the unique styles may be eliminated.
In reality, something this extreme is unlikely to happen all the time, but mechanisms essentially similar to this are likely operating everywhere.
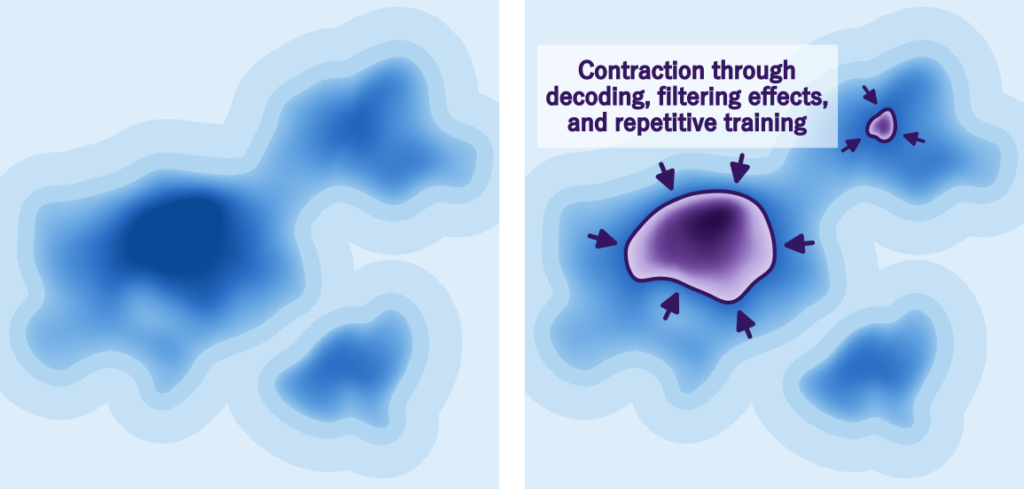
AI-generated data has an effect of contracting toward typical, high-quality data because of decoding methods and filtering. Human-generated data is diverse, but adding AI-generated data to training data causes the data distribution to contract toward the center. In reality, both the contraction effect of AI and the frontier-expanding effect of human creativity operate simultaneously, and diversity is probably realized at the point where they balance. However, as the proportion of AI-generated content increases in the future, there is concern that the contraction effect will strengthen and diversity will decrease.
The trade-off between diversity and quality
Over the past few years, it has been reported almost every month, even every week, that state-of-the-art AI has updated some benchmark. I think the background to the gap between these overwhelming reported high scores and the somewhat underwhelming performance one sometimes feels in practice lies in this trade-off.
Humanity, as collective intelligence, may know 100 ways to score 80 points, whereas AI may know how to score 80 points but know only one way to do it. On a benchmark, both are scored as 80 points, but the meaning of those 80 points is different.

The figure above is an example of a poster created with AI. Some viewers may feel a certain “AI smell” from it, but if you set aside that preconception and look at it with the sensibility of around 2020, it seems, at least to an amateur eye, like a fairly good poster. It is difficult to assign a score to a poster, but let us give it 80 points here. This is a much higher score than image generation AI from several years ago. It may even be a higher score than a poster made by someone without special training.
However, there should be many other kinds of 80-point posters. Humanity, as collective intelligence, knows countless ways to make such posters. AI probably does not know only this one kind either, but compared with humanity as a whole, its repertoire is essentially much smaller. The sense that an image or design has an “AI smell” can be understood as arising from the essential narrowness of AI’s repertoire: because people repeatedly see similar patterns, they naturally become able to recognize those patterns. If AI truly covered the full diversity of humanity, people should not be able to recognize an AI-like visual style. The output distribution of AI has a strong bias, and that bias is perceived as a smell. When there is a breakthrough in AI, it is initially received with fresh surprise, but gradually starts to feel stale. This kind of mechanism may be one reason why.
AI has acquired the ability to score highly on benchmarks and is approaching, and in some fields surpassing, humanity’s highest scores. But humanity, as collective intelligence, knows countless ways to achieve the highest scores, whereas AI may know far fewer ways to achieve high scores.
This also becomes a problem when we use AI as a tool. Coding agents and research agents often reach a solution at tremendous speed in a straight line, but once they get stuck in a quagmire, they can fail to make progress indefinitely, and humans have to clean up the mess. One reason may be that while AI has several powerful abilities, it lacks the broad repertoire of modest, unspectacular, yet important basic capabilities that make up the tails of the distribution.
Modern AI is beginning to surpass the abilities of excellent individuals, but it probably does not yet possess enough ability to cover the collective intelligence of humanity as a whole. I believe this is difficult to solve with modern AI. AI is, after all, a finite model. It may be able to contain something on the scale of an individual’s ability, but it still seems far too small to contain the diversity of all 8 billion humans. What makes this area difficult to recognize correctly is that modern AI has broader diversity than the diversity within each individual person, so from an individual’s perspective, using AI feels like an expansion of one’s abilities and an increase in the range of things one can do. At the same time, because all humans are experiencing this uniformly, humanity as a whole may become less diverse. This limitation may be resolved in the future through scaling, but it does not seem like something that can be solved in the short term with small technical tricks. It will likely take time.
This can also offer a path forward for humans whose work is being taken over by AI. People who can only make 80-point posters have been caught up to by AI, but an 80-point poster of a kind that AI cannot make has value beyond its score precisely because it is a pattern AI cannot produce. This is true from a short-term perspective, because people already feel an AI smell in AI-generated works, or even if they do not consciously feel it, they may unconsciously feel a kind of fatigue, and therefore may begin to perceive AI-generated works that should originally score 80 points as having lower value. It is also true from a long-term perspective, because in order to secure the diversity of humanity’s content as a whole, content that cannot be created by AI alone will become even more important even when it has the same score.
However, what is valuable is probably not being able to create “that” one unique work, or having “that” one unique style. Repeating the same style can be a powerful means of expression, but from the perspective of differentiating oneself from AI, it has the same weakness as the staleness of AI. What is valuable here is having a broad repertoire, something like fundamental strength. Just as one diversifies a portfolio under high uncertainty, in this uncertain era I feel that having a broad repertoire is important for survival.
The common saying that “routine work should be left to AI, and humans should focus on creative work” also seems related to this structure. Creative work, that is, continuing to explore the lightly colored tails of the distribution, will still have value even after AI develops and becomes highly capable, and perhaps especially after it becomes highly capable.
The loss of diversity in iterative training can have a positive effect on training
So far, I have discussed loss of diversity from the standpoint that it is bad. However, the low diversity of AI outputs can have a positive effect for later AI, in the sense that it makes patterns easier to learn.
Suppose the average score of the AI outputs currently at hand is 70 points. If we randomly sample 10 people from humanity as a whole and have them create 10 pieces of 80-point data as teacher data, those 10 pieces may be so diverse that the model cannot find common patterns and may fail to train well. On the other hand, if we generate a large amount of data from the AI at hand, select 10 pieces that happen to score 80 points, and use them as teacher data, those 10 pieces have many commonalities and are already familiar to the AI, making them easy to learn from and highly effective. This has been reported by [Chen+ ICML 2026].
However, it is important to note that the performance improvement from this method is probably not a fundamental expansion of diversity, but rather a one-time performance improvement that assumes a dead end will eventually be reached.
Mitigation: prompt engineering
The loss of diversity caused by AI can be mitigated by using unique prompts.
As mentioned above, when you speak casually to ChatGPT in English, it almost always responds in standard American English. However, if you give prompts such as “speak in British English” or “speak in Australian English,” it can speak in other dialects as well. In other words, ChatGPT is not completely incapable of speaking anything other than American English. The ability is latent, and it can be drawn out by giving the right trigger. As we have seen, AI outputs lack diversity in the default mode, but if users each give diverse instructions according to their own preferences, such as British English or Australian English, the overall result becomes more diverse than the default mode.
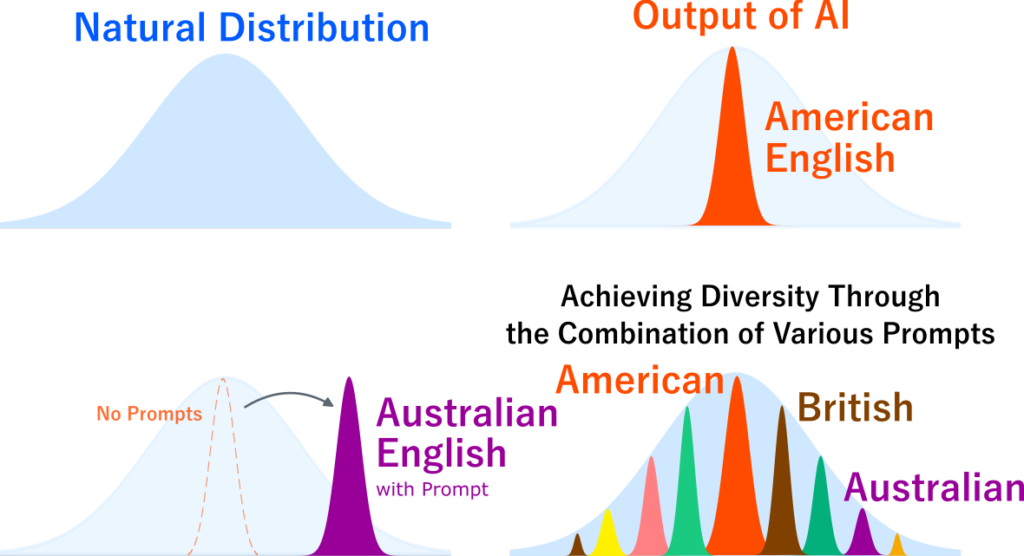
As we have seen, because of decoding and filtering, if one fixes a setting or prompt, the data generated by AI under that condition does not reflect the natural data distribution and lacks diversity. But changing the prompt makes it generate a different distribution that also lacks diversity. Each individual distribution may lack diversity, but by superimposing them, as in the figure above, the overall distribution can become diverse. In particular, by using unique prompts that no one else would think to give, it is possible to generate data from the tails of the distribution. In other words, as long as one leaves generation to the default mode without prompt engineering, diversity greatly decreases. But by using unique prompts, one may be able to contribute to diversity.
However, this does not solve the entire problem of diversity. In fact, [Hataya+ ICCV 2023] also tried diversifying prompts. Although there was a slight positive effect, the effect was limited, and the results were far worse than when natural data was used.
In LLMs and other AIs, there are patterns that are generated naturally without any conditioning, patterns that can be drawn out only through careful prompting, and patterns that are not stored in the model in the first place. Suppose there is an enormous amount of training data, almost 100 percent of it is in American English, and British English accounts for almost 0 percent. In that case, British English will not be output naturally. However, even if its proportion is almost 0 percent, if the model has seen tens of thousands of British English examples in absolute terms during training, British English is latent in the model and can be drawn out by giving an appropriate prompt.
However, models cannot cover all the data they saw during training. Data that appeared only once or twice during training is highly likely not to be memorized at all, and probably cannot be drawn out no matter how cleverly one prompts. Model capacity is finite. As noted above, if an eccentric style has a relatively low score, it may be eliminated from memory as a result of optimization in order to use memory capacity efficiently. From the perspective of preserving diversity, precisely such tail data is important. But from the perspective of memory efficiency, such tail data is inefficient and is therefore discarded. In other words, because model capacity is finite, there are limits to the approach of trying to draw things out from the model. This limitation may look trivial from the perspective of an individual, but it can become a fundamental problem for the sustainable development of AI.
The same applies to LoRA and fine-tuning. LoRA and fine-tuning can draw out the abilities of a foundation model more powerfully than prompting, but they cannot draw out something that is not latent in the foundation model in the first place.
Cost-effectiveness also deserves attention. When a new AI appears, it is greeted with surprise because even its default mode shows new patterns we have never seen before. But those patterns gradually become tiresome. With some degree of prompt engineering, one may be able to draw out fresh patterns, but those too eventually run out, and it becomes necessary to make more and more effort to draw out new patterns. At that point, the required effort may no longer offer the level of cost-effectiveness that people felt when the AI first appeared. In the end, for things that require high originality, it may become faster to create them oneself without relying on AI.
As models become larger, they may have more room to retain data that does not naturally emerge, and this trade-off may be alleviated. However, as mentioned earlier, modern models still seem too small to contain the diversity of humanity as a whole, and a complete solution still appears to require time.
In other words, devising unique prompts is not a fundamental solution by itself, but it can be effective in the sense that it applies a brake to AI’s contraction effect on diversity. Still, it does not solve everything on its own. Normatively speaking, one could say: If you use AI, it is better to use original prompts than to rely on default generation. That can contribute to diversity. But ultimately, in order to maintain diversity, we need to keep creating without relying on AI.
AI’s evolution also affects human behavior
This problem is not only that AI becomes inconvenient as a tool. Now that many people collaborate with AI, a decline in AI diversity may also negatively affect the diversity of humanity as a whole.
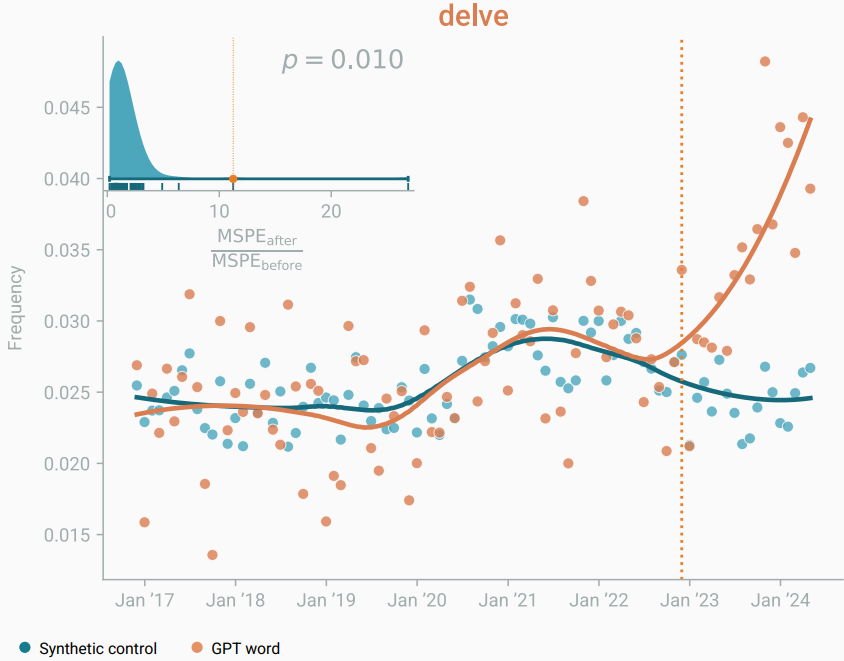
A study by Yakura of the Max Planck Institute for Human Development and colleagues [Yakura+ arXiv 2024] shows that the habits of LLMs also affect human spoken language. It is easy to imagine that LLMs influence written language, or that LLM expressions propagate through copying and pasting. But the fact that they also affect spoken language suggests that LLMs are influencing deeper human behavior patterns. More specifically, the authors listed words such as “delve” and “comprehend,” which humans do not use very often but ChatGPT uses frequently, and conducted a large-scale analysis of transcripts of human speech from podcasts, YouTube videos, and other sources. They found that compared with other words, the spoken frequency of these “GPT words” increased significantly after the emergence of ChatGPT. The increase was significant even in casual speech without prepared scripts, suggesting that the influence extends not only to written text but also to speech patterns emerging from within humans themselves. If AI diversity decreases, habits with such low diversity may permeate humanity as a whole, and overall diversity may shrink. This study suggests that the vortex of diversity contraction has left the LLM itself and is beginning to engulf humanity as a whole. Even people who have never used ChatGPT may hear colleagues or their favorite YouTubers speak “GPT words,” unconsciously start using “GPT words” themselves, and then further propagate those habits.
In a study by Marwa Abdulhai of Google DeepMind and UC Berkeley and colleagues [Abdulhai+ arXiv 2026], 100 participants were divided into a group that did not use LLMs and a group that was allowed to use LLMs. They were asked to write an essay on the topic “Can money buy happiness?” The study reported that among users who heavily used LLMs to write their essays, the proportion who avoided taking a clear pro or con position and instead fled to a neutral answer increased by 70 percent compared with the group that wrote on their own. AI tends to converge on safe conclusions that avoid making waves, such as “money provides basic needs, but true happiness lies in human relationships.” If AI diversity decreases, there is concern that the diversity of our own expressions of opinion, mediated by our use of AI, will shrink as well.
In other words, the previous sections discussed the decline of AI diversity through iterative training, but humans influenced by AI may be pulled into the same decline of diversity.
Conclusion
I believe the decline of diversity caused by AI is a serious long-term concern. Worse, it may progress without people being aware of it. We can no longer imagine a world without AI, and it will become difficult, especially for residents of a world whose diversity has already diminished, to imagine what rich diversity would have existed in a world that had continued without AI. In a sense, the fact that people feel an “AI smell” is a healthy response to this. People sometimes try to remove the “AI smell” from AI-generated works, and sometimes even from things humans made entirely by themselves. This may look comical at first glance, but from the perspective of maintaining diversity, I think it is a meaningful effort. I said that ultimately, in order to maintain diversity, we need to keep creating without relying on AI. But even without being told this, people who keep creating will keep creating. In reality, thanks to such people, humanity’s diversity will not completely collapse and converge to one thing. I, too, want to keep creating as long as I can, while carefully watching what level of diversity we converge to in the struggle against AI’s contraction effect.
I hope this article serves as an opportunity to think deeply about AI and diversity.
Author Profile
If you found this article useful or interesting, I would be delighted if you could share your thoughts on social media.
New posts are announced on @joisino_en (Twitter), so please be sure to follow!

Ryoma Sato
Currently an Assistant Professor at the National Institute of Informatics, Japan.
Research Interest: Machine Learning and Data Mining.
Ph.D (Kyoto University).

