
I came across an intriguing post while browsing X during New Year’s holidays.
Historically, humanity has pursued the idea that truth is inherently simple, exemplified by equations like \(E = mc^2\) or \(F = ma\). However, the idea presented was that such truths may represent only a small subset of the entire truth, suggesting the existence of truths so complex that they are beyond human comprehension.
❌“If AI becomes more intelligent than humans in both quality and quantity, humans will not be able to understand it.”
✅”This world was originally structured in a way that humans cannot fully understand, and AI will be able to handle it.”
I think it would be better to have a worldview like this.
It reminds me of the discussion on adversarial examples around 2018. In this article, I revisit these discussions in light of recent advancements in AI.
AI Uses Information Imperceptible to Humans
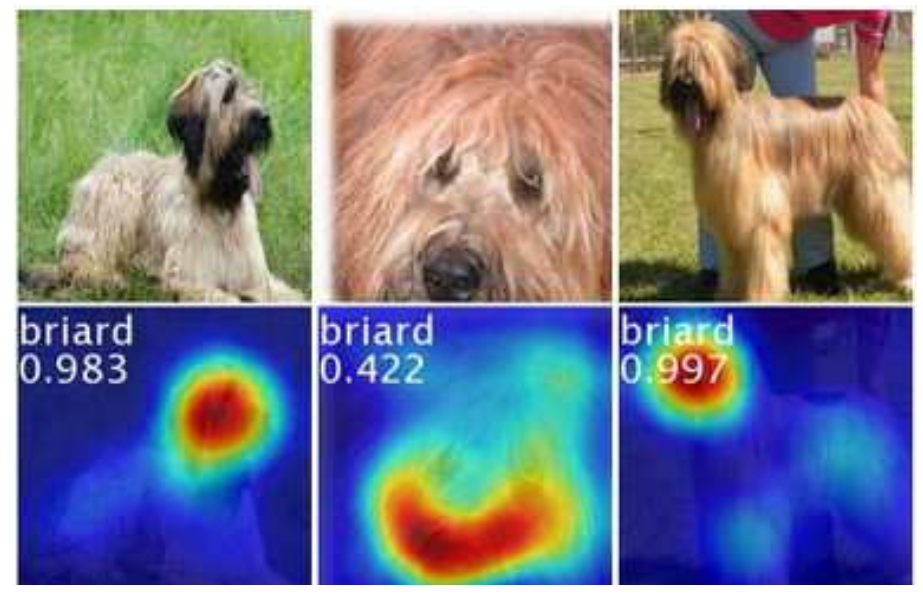
You might have heard of adversarial examples. They involve adding slight, noise-like patterns to images—for example, causing models to classify a dog’s image as a cat, despite the image appearing unchanged to human eyes.
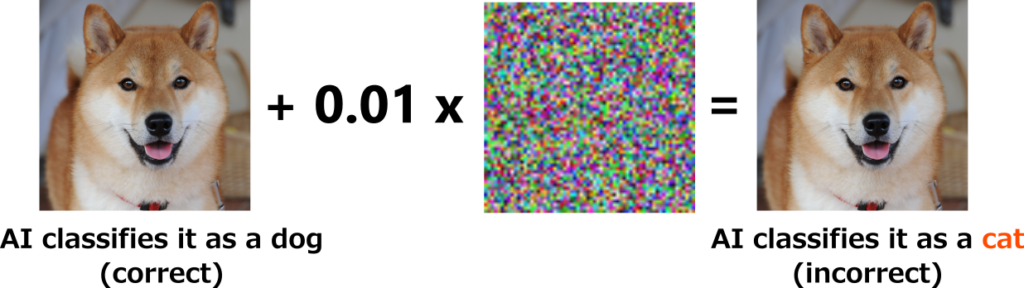
Initially, such behavior was mocked as evidence of the “stupidity” of AI. However, Ilyas et al. [Ilyas+ NeurIPS 2019] revealed that the actual misunderstanding lay with humans.
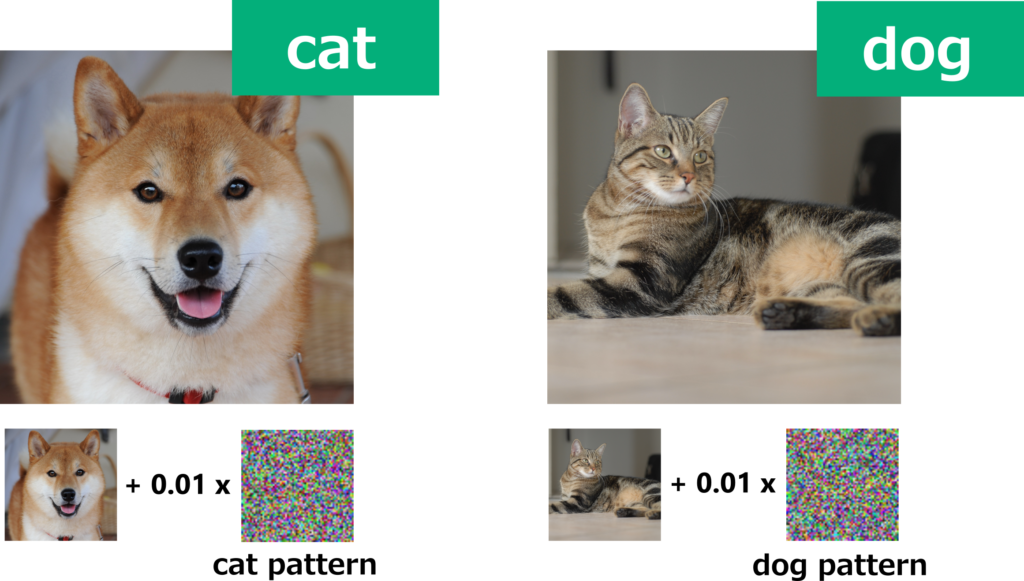
In the past, this kind of noise-like pattern was believed to be a meaningless pattern that was only for fooling the model. However, when it was analyzed in detail, it was found that this pattern contains strong characteristics unique to cat images (although humans cannot perceive it), and that it appears in cat images but not in dog images. Therefore, classifying images that contain this pattern as cat images is a rational decision in a sense. The synthesized image (above right) has features like a dog’s big tongue and black nose, so to humans it looks like a dog, but because it contains a pattern that only appears in cats, overall it is actually quite a cat-like image (even if humans can’t tell). The humans couldn’t see it, but the AI was smart enough to see it.
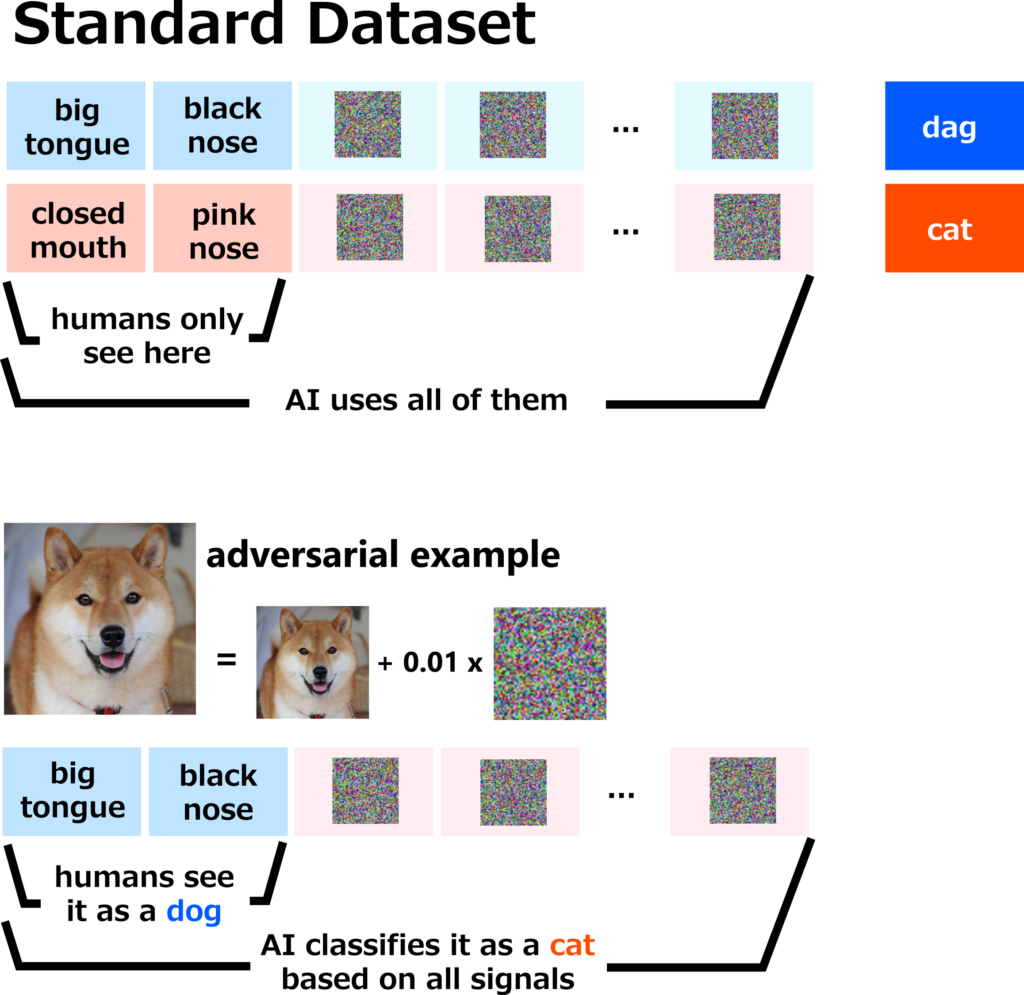
Ilyas et al. [Ilyas+ NeurIPS 2019] demonstrated this through an elegant experiment, generating data that deliberately misled humans but not models.
We create a training dataset by labeling the adversarial image mentioned above (image of a dog + 0.01 x adversarial cat-like pattern) as “cat” and similarly labeling the (image of a cat + 0.01 x adversarial dog-like pattern) as “dog”. This adversarial pattern is created for Model A, which was created by training normally beforehand. This Model A will be discarded after the dataset is created.
The images that look like dogs to us have been labeled “cat”, and the images that look like cats to us have been labeled “dog”, so it looks like a completely misaligned dataset to humans.
As a thought experiment, let’s show these false images to a young child who has not yet learned to distinguish between dogs and cats, and keep telling them “This is a dog” and “This is a cat”. After the child has learned to distinguish between dogs and cats, if you show them a newly taken image of a normal dog (a normal image with no adversarial patterns), they will probably answer “Cat!”. This is to be expected, since we have been making them call things that look like dogs “cats” and things that look like cats “dogs” (please don’t actually do this).
On the other hand, what would happen if we trained a machine learning model (such as ResNet-50) with this data? Surprisingly, when we show it a newly taken image of a normal dog (a normal image with no adversarial patterns), it will correctly answer “dog”. This is because it learned during training that if an image contains dog-like patterns (which humans cannot see), it is labeled “dog”. It was also able to use this information during the test and answer “dog”. Of course, according to this fake dataset, normal dog images exhibit “cat features” such as a big tongue and a black nose (in this fake data set, these are cat features), the AI may classify it as a cat, but it is important that the AI answers “dog” correctly with a high probability, whereas humans who have learned from this dataset will definitely answer “cat”.
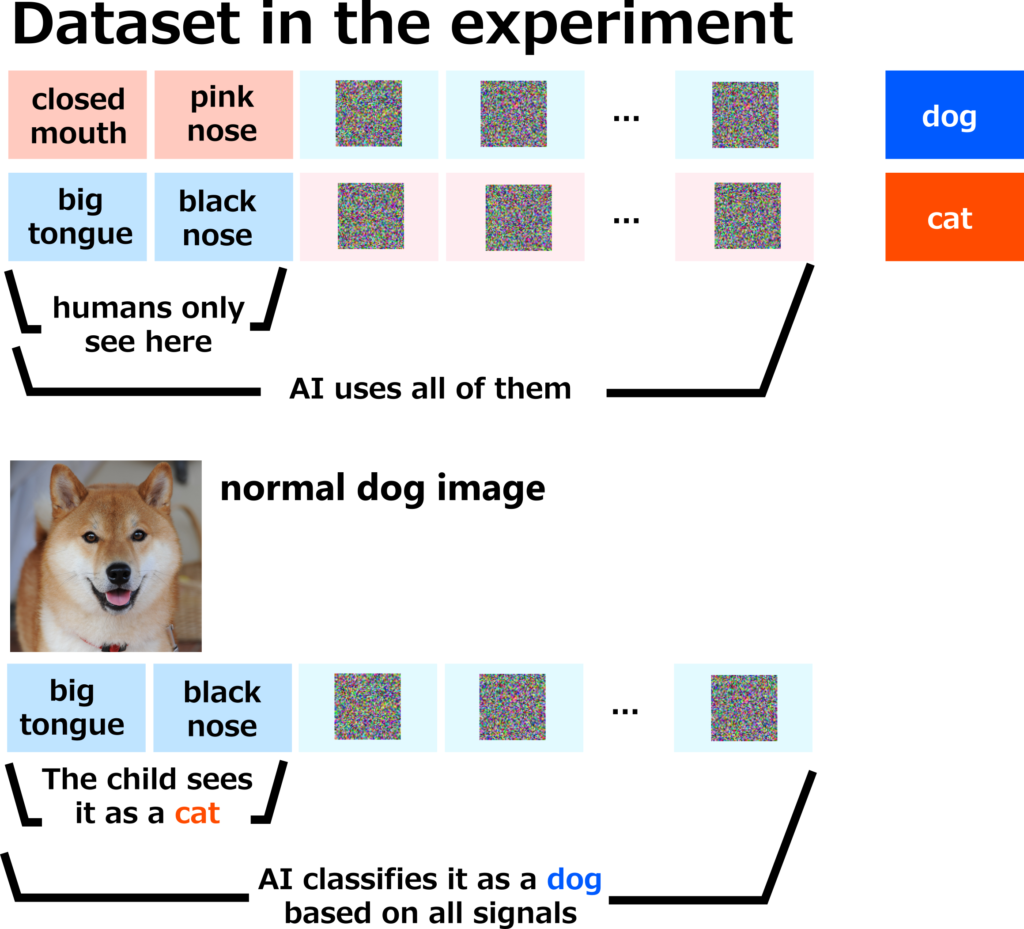
The experimental data set looked completely wrong to us, and we didn’t think that learning with such data would enable the classification of cats and dogs, but it was only humans who thought that. The dataset contained valid clues for classifying cats and dogs. In fact, the AI was able to learn from these clues and give the correct answer even for normal images it had never seen before. In other words, these patterns were not random noise, or a quirk unique to Model A, or a quirk unique to this training data – they were valid clues that enabled the AI to classify dogs and cats. Features such as a big tongue or a black nose are only a small part of the clues that distinguish dogs from cats, and there are actually various clues like the patterns that can be used to distinguish between dogs and cats. The humans couldn’t see these clues, and were fooled by only looking at the superficial information. On the other hand, the wise AI was able to read even information that humans couldn’t perceive, and was able to get the correct answer from this data set.
Incidentally, if we restrict the AI in such a way that it cannot see these patterns, and make the information it can observe the same as that of humans, it learns similar classification rules as humans, and the predictions will not be reversed by adversarial attack, and it will not be able to learn valid classification rule from the fake datasets in the experiment above as humans. The important thing is that when we restrict the AI’s capabilities, it becomes the same as humans, but if we do not restrict it, the AI can also utilize information that humans cannot perceive, and it can deal with a wider range of problems.
In this experiment, we deliberately constructed the dataset so that this would happen, but there may be data in nature like this example, where humans can’t learn to classify it no matter how much they learn, but AI can learn it.
AI Uses Subtle Information
We can construct a simple example of this kind of “information that humans cannot perceive but AI can perceive”. Consider the following dataset by Dimitris Tsipras et al. [Tsipras+ ICLR 2019].
Positive data:
The first dimension takes the value 1 with probability 0.95 and the value -1 with probability 0.05.
The 2nd to 1,000,001st dimensions are independently and normally distributed with a mean of 0.01 and a variance of 1.
Negative data:
The first dimension takes -1 with a probability of 0.95 and 1 with a probability of 0.05.
The 2nd to 1,000,001st dimensions are independently and normally distributed with a mean of -0.01 and a variance of 1.
The positive and negative examples are split evenly.
For example, the data (1.000, −1.476, 0.660, 0.076, …, −1.327) looks positive. In the positive data, the probability of taking the value 1 in the first dimension is quite high, while in the negative data, the probability of taking the value 1 is quite low. This data looks positive because the value is 1.
The second dimension is negative (-1.476), but on its own this is not a very strong clue for negative data. In fact, \(p_+(−1.476)=0.132\) and \(p_−(−1.476)=0.136\), and the probabilities are almost the same. Here \(p_+\) is the probability density function of the second dimension in the positive examples, and \(p_-\) is the probability density function for the negative examples.
However, although the information in each dimension is subtle, strong information can be obtained by combining them. Let’s consider a linear classifier \(\text{sign}(w^\top x)\) with weight \(w = (0, 1/d, 1/d, \ldots, 1/d)\) and \(d = 1\,000\,000\). This is a function that outputs the sign of the average of the values in the 2nd ~ 1,000,001st dimensions. Since the standard deviation of the average of 1,000,000 signals is 1/1000, and the positive example has a mean of 0.01 and a standard deviation of 0.001, the negative example has a mean of -0.01 and a standard deviation of 0.001, so the probability of making a mistake is less than 0.000001, and in terms of accuracy, it is more than 99.9999%.
In other words, even if the information in each factor is too subtle for humans to perceive, if we collect a large amount of it, it can become a strong clue.
It is easy to understand that the first dimension contributes to label prediction, and it is also easy for humans to interpret. However, if you only use the first dimension, the accuracy will only be 95% at best. If you want to achieve a higher level of accuracy, you need to make use of information from the other dimensions. However, the problem is that these signals are difficult for humans to perceive. If they are expressed as numerical values as shown above, it is still possible for humans to calculate them if they spend enough time on it, but when they are expressed in the form of the image shown at the beginning of this article, it is impossible for the human eye to recognize how many tiny patterns are superimposed on top of each other.
Problems that Cannot Be Solved with Reductionism
In science, we often break down complex objects into simple factors and discuss them. For example, we say that smoking increases the risk of lung cancer, or that eating XXX reduces the risk of lung cancer.
However, as we can see in the above example, even if the individual factors are not statistically significant or the effect size is small and they are so weak that they are overlooked, they may solve the problem when combined. Conversely, this means that there are problems that cannot be solved if we investigate each factor one by one, asking “Does this factor contribute to the result?” and “Does this factor contribute to the result?”, and so on.
AI’s Decision We Cannot Interpret
In order to understand AI that is so complex and clever that it is beyond human understanding, there are many methods being researched to interpret how the AI made its decision. However, there are also problems that cannot be solved in this way.
In the above, we considered the first dimension for the sake of explanation, but here we will delete the first dimension because it is getting in the way. In other words, we will consider data with 1 ~ 1,000,000 dimensions, where the positive example data follows a normal distribution with a mean of 0.01 and a variance of 1, and the negative example data follows a normal distribution with a mean of -0.01 and a variance of 1. Even with this distribution, if we construct a linear classifier using the same method as above, we can solve this problem. In other words,
\(x=(−1.259,0.668,−0.200,−0.213,0.656,−0.541,−0.018,…,−0.838)\)
if we show the AI data like this, the AI will classify it as a positive example,
\(x=(0.489,−2.062,−0.649,0.203,0.602,0.440,0.307,…,−0.905)\)
if we show the AI data like this, the AI will classify it as a negative example. Furthermore, this prediction is correct over 99.9999% of the time.
However, the difference between the data is quite subtle, so it is impossible for humans to understand why the AI makes such decisions and why it always makes correct answers. Let’s say we want to know how the AI came to give the above data a positive example and the below data a negative example.
There are well-known methods for interpreting how the AI made its decision, including class activation mapping (CAM), which identifies the dimensions and parts of the data used to make the decision, and attribution methods, which calculate how much each dimension contributed to the result.
However, in the case of the example above, it is difficult to identify which part is important. Even if you apply this kind of visualization method, all the dimensions will be highlighted in red and it will be useless. Even if we ask “where did you look in the end?” or “answer one factor that you focused on the most”, the AI can only say that it considered all the factors equally. Or, it might be able to show the dimension with the largest value in the positive examples, but even if there is a large value such as 5.14, there is a good chance (almost the same probability as the positive examples) that a negative example will also have a value of around that level if there are 1,000,000 dimensions. If you just accept that it was a positive example because this dimension was 5.14, you will mistakenly judge it to be a positive example when another negative example with a large value comes along. Even if you look at each dimension, there is only a difference that is too small for humans to perceive (and too small to be statistically significant), so it is not possible to understand at a glance why each data is a positive or negative example. For simplicity, we have used the number of factors (dimensions) as a measure of complexity here, but the argument is the same no matter what complexity measure we use, such as nonlinearity, narrow margins, or description length. Ultimately, if the underlying rule itself is inherently complex, it can only be explained in a complex way, and even if there is a simple explanation that can be approximated to the point where it can be understood by humans, it is only an approximation and so it could contain errors.
Then, What Can We Do?

So, when AI becomes too smart and humans can no longer understand what it is doing, is there nothing we can do but submit to it and place our trust in it? That can’t be right.
Use AI as A Feature
When it is enough if the prediction is correct, the output of AI can be considered as part of the environment, just like other natural signals, and can be used as a basis for human prediction.
We can predict the weather for the next day by, e.g.,
“If there are large cirrus clouds in the western sky in autumn, it will rain the next day,” and
“If this AI says it will rain the next day, it will rain the next day.”
There is no reason to think that relying on the feature of cirrus cloud is “natural” and relying on the “signal from the AI” is “unnatural”. Suppose we discovered that “when the clouds take on this shape, there is an extremely high probability of rain the next day”. Other discoveries such as “when this AI answers yes, there is an extremely high probability of rain the next day” should be no less useful. The AI may even be easier to control and scientifically analyze than nature. We can think of it as a new discovery that such a very useful signal for prediction has appeared in the environment.
Even If We Can’t Understand the Reasoning Process, We Can Still Verify It.
Even if we can’t understand the reasoning process, we can still do the verification.
Many problems in science can be divided into exploration and verification, and exploration is often more difficult while verification is often easier. So, by leaving the exploration to AI and having humans take charge of the verification, we can safely advance science while making the most of AI’s capabilities.
For example, it is very difficult to design a protein that is effective against a certain disease, but when a promising protein is found, it is relatively easy to verify whether or not it is actually effective against the disease. Even if we don’t know why such a protein was created, we can think that it is great because a useful protein was created. In fact, there must have been cases where useful proteins were designed based on the inspiration of genius scientists, and even if the process of how they came up with the idea and what kind of thought process they went through to come up with it cannot be explained, the fact that a useful protein was obtained as a result is sufficient, and we “know” that it is useful. It is also possible to put it to practical use and make it useful for society.
There are many studies in this direction, including Alpha Fold, and I also think that the direction of “leaving the search to AI and having humans take charge of verification” is promising for actually utilizing AI in science.
This structure of “search is difficult, verification is easy” appears in various situations.
NP-completeness captures this structure well.
Let’s consider the Hamiltonian cycle problem. A Hamilton cycle is a path that returns to the starting point by passing through every point exactly once. You cannot pass through the same point more than once, and every point must be visited.
Finding a Hamilton cycle from a graph is a difficult problem, but it is very easy to verify whether a given path is a Hamilton cycle.
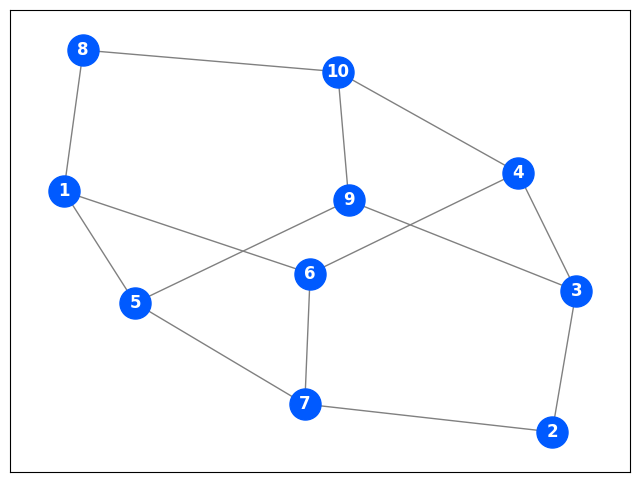
For example, can you find a Hamiltonian cycle in the following graph? The edges cross, but you can only go straight at those points; turns are only allowed at vertices.
The answer is the following path:
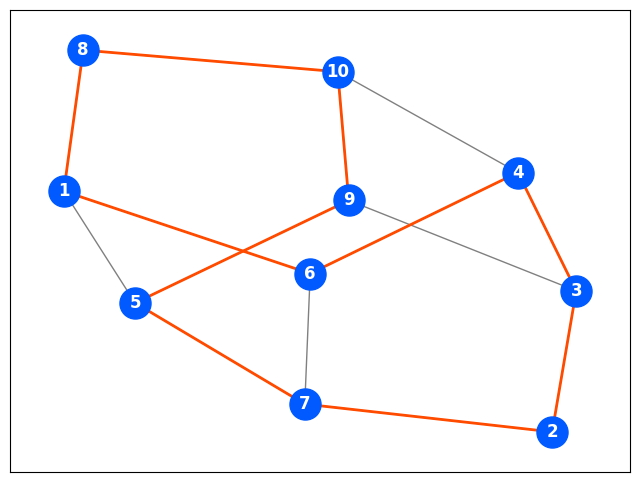
If the number of vertices is around 10, it’s manageable, but as the number increases to 20, 30, etc., it becomes exponentially more difficult to find a Hamiltonian cycle.
On the other hand, checking that a path is a Hamiltonian cycle only requires effort proportional to the number of vertices, as we only need to check whether the path returns to the starting point and passes through each point exactly once.
Even if you are only interested in whether or not a Hamiltonian cycle exists in a graph, and you don’t actually need a Hamiltonian cycle itself, it is important to have the AI output a Hamiltonian cycle as evidence, rather than just having it say “it exists”.
When the AI solves the Hamiltonian cycle problem, it may not be able to explain to a human how it found the Hamiltonian cycle, and even if it does explain, it may be something that humans cannot understand or imitate. Even so, if we are given evidence, then we are certain that the Hamilton cycle problem for that graph has been solved.
It is also important to note that, even under the worst-case scenario of a science fiction-like “malicious AI”, we can make good use of AI without being deceived by it, using this structure of problems. If humans are unable to find a Hamiltonian cycle, and only AIs are able to find them, even if a malicious AI tries to trick humans by outputting a Hamiltonian cycle-looking path that is actually not a Hamiltonian cycle, humans with limited ability can still reliably determine whether it is actually a Hamiltonian cycle or not. Using this structure of problems, even if we don’t understand why or how the AI came up with that answer, we can still safely make effective use of the result.
There are also more sophisticated methods of verification than simply having the AI output a single path. For example, let’s say we want to know how long it will take to visit all the tourist spots in the shortest possible time (i.e. we want to solve the traveling salesman problem). Rather than having the AI just output a predicted time, we can have it output “the optimal value is at least X and at most Y”, and as evidence, output a route of length Y and a dual solution with objective function value X. Even if we can’t work out how the AI came to this conclusion, it’s easy to check that these are in fact a route of length Y and a dual solution with objective function value X, and we can be convinced that the “optimal value is at least and and at most Y” (from weak duality). We can also be confident that this path is optimal when X = Y. In this problem, if the AI is only asked to output one route, there is a possibility that a malicious AI will output a bad route, and we will not be able to notice that there is a better solution. The key insight here is that by using a duality problem, it becomes possible to verify it by bounding it from above and below. In addition, by using the techniques of the interactive proof system [Goldwasser+ STOC 1985], it is possible for humans with low ability (verifiers) to verify with confidence problems in a wider range than NP (for example, IP = PSPACE or MIP = NEXPTIME) by communicating repeatedly with an AI (prover) or communicating with multiple independent AIs (provers).
It is not necessarily the case that humanity will be content to settle for “verification work” = “simple work”. In the past, when humanity was both exploring and verifying, exploration was the bottleneck, so at best only problems that humans could reach through exploration could appear, and verification of those problems was simple work. However, when humanity is free from exploration with the aid of AI, the range of problems that can be handled will expand dramatically, and verification work will become the bottleneck in advancing human knowledge. Difficult problems that are just about within the limits of human verification will arise, and in this area, verification work will also be a challenging and attractive task for humans.
Humans can determine the formulation of the problem of what data to input into AI and what to output. I think it is important for humans and AI to cooperate in advancing science in the future by considering problem formulation that makes the black box of AI thinking bear as much of the burden as possible of tedious exploration and outputs it in a form that is easy for humans to verify.
Conclusion
The discussion on adversarial examples was greatly influenced, directly and indirectly, by the research of Alexander Madeley’s group. I would like to express my acknowledgements here.
The topics discussed in this article are still being actively debated, from issues that actually arise in the field of scientific research to science fiction-like speculation, and there is no clear correct answer, and is likely to spark debate. I would be happy if you could post your thoughts and impressions on social media.
Author Profile
If you found this article useful or interesting, I would be delighted if you could share your thoughts on social media.
New posts are announced on @joisino_en (Twitter), so please be sure to follow!

Ryoma Sato
Currently an Assistant Professor at the National Institute of Informatics, Japan.
Research Interest: Machine Learning and Data Mining.
Ph.D (Kyoto University).

