
AI performance is improving day by day, and its evolution may appear unstoppable. However, in reality, that is not what will happen. In this article, I explain why.
The key terms in this article are epistemic uncertainty and aleatoric uncertainty. Epistemic uncertainty is uncertainty that can be resolved through observation, whereas aleatoric uncertainty arises from intrinsic randomness and therefore cannot be eliminated no matter what.
When you wake up in the morning, the blackout curtains are closed, and you cannot see outside at all. At that moment, the weather outside is an example of epistemic uncertainty. If you open the curtains, you can resolve that uncertainty.
Epistemic uncertainty can also be reduced through training. Before you learn how to ride a bicycle, you do not know how much momentum you will get by pressing the pedals with a given amount of force. At that point, epistemic uncertainty is large. But after riding a bicycle many times, you observe many patterns of how much speed you get from how much force, and eventually you can predict it almost certainly. Training has reduced epistemic uncertainty.
When rolling a die, the outcome is an example of aleatoric uncertainty. No matter how many times you roll the die and observe the patterns, there is a limit to how much predictive ability you can acquire for the next outcome.
This discussion also applies to AI.
The core function of AI is prediction. LLMs repeatedly predict the next token. Diffusion image generation models also repeatedly predict images from noise.
Any AI initially makes only random and inaccurate predictions. Through training, it becomes able to predict the correct tokens or images. This is a reduction in epistemic uncertainty.
However, aleatoric uncertainty exists in the world, and AI cannot predict it no matter what it does.
No matter how advanced an AI may be, it cannot accurately predict the next outcome of a die roll.
In many real-world prediction problems, such as forecasting tomorrow’s weather, predicting the mood of the person replying to an email, recommending content that matches a user’s mood, or predicting the next character a user will type, epistemic uncertainty and aleatoric uncertainty are mixed together.
In fact, in the scaling laws of LLMs, it is widely known that there are reducible and irreducible errors. For the reducible part, the error decreases polynomially as more cost is invested. But irreducible error always accompanies this.
So far, the reducible error has been dominant in AI progress. That is why each time more cost was invested to AI, the error fell by a fixed proportion.
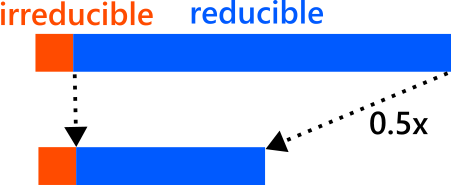
Training foundation models requires enormous cost, but because prediction performance kept improving as more cost was invested, large amounts of money were poured in, and this is how AI achieved improvements in predictive performance.
However, once AI has more or less exhausted the error it can reduce, the remaining irreducible error begins to stand out. At that point, even if you spend 10 times more, the error hardly decreases at all.
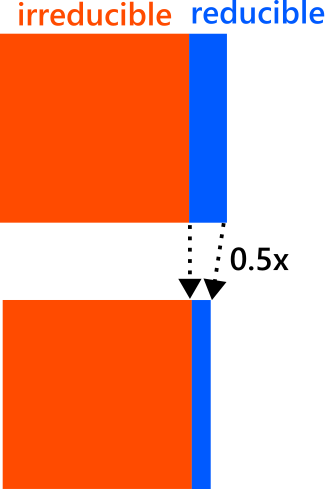
As we approach this stage, it is no longer economically rational to spend more in order to improve predictive performance. In principle, there may still be some error left that could be reduced, but once the cost required to do so is taken into account, the return becomes so absurdly small that no company will choose to do it. At that point, the growth of foundation models stops.
There is another way to reduce epistemic uncertainty: to let AI itself make observations. Up to this point, I have discussed reducing epistemic uncertainty through learning, but within irreducible error there may also be epistemic uncertainty that can be reduced through observation without training. For example, if the blackout curtains are closed, no matter how smart a person is, they cannot know the weather outside. But if they open the curtains, they know the answer instantly.
All recent approaches such as RAG and agentic AI are, in essence, attempts in this direction. In other words, they try to reduce epistemic uncertainty by having AI gather information itself and then observe that information.
However, this approach has a problem: it incurs cost every time. Opening the curtains takes effort. Searching takes effort. These may be tiny costs, but if they are incurred every single time, then many small costs add up to a large one. This is a different kind of growth from growth through training.
Fundamentally, this is an amortization problem. Once foundation model training has been done, you can keep receiving its benefits afterward. That is why it was considered worth the enormous cost, and why recovering that cost was realistic. In other words, increasing the capabilities of a foundation model worked in the direction of lowering per-use cost.
But for approaches that incur cost every time, the situation is the opposite. Naturally, from the standpoint of per-use cost, they push cost upward. Growth in this direction has limits. Even a small increase in cost must be borne every single time, so little cost can be justified. At that point, growth along this direction also stops.
Finally, there is one more factor that stops AI progress: a social factor.
There is a dilemma in which, as AI spreads throughout the world, AI becomes unable to predict the world.
This is easiest to understand with the example of an AI that predicts stock prices. What would happen if an AI that could accurately predict stock prices appeared and became widely used? Everyone would begin trading based on that AI, the rules of the market would change, and that AI would no longer be able to predict stock prices.
The same applies to questions such as what will happen in society in the future, what markets will look like, and what social needs will become. Even if an AI that could accurately predict such things were somehow created, the moment it became widespread in society, it would become unable to predict that society. In other words, AI can never fully solve such problems.
AI may continue to spread throughout society, and we may entrust it with ever more advanced tasks. But advanced tasks and advanced decision-making involve, at least indirectly, questions such as what will happen in society going forward. There is a dilemma in which the more AI spreads through society, the less able AI becomes to solve such prediction problems. For that reason, AI progress will eventually come to a halt.
Author Profile
If you found this article useful or interesting, I would be delighted if you could share your thoughts on social media.
New posts are announced on @joisino_en (Twitter), so please be sure to follow!

Ryoma Sato
Currently an Assistant Professor at the National Institute of Informatics, Japan.
Research Interest: Machine Learning and Data Mining.
Ph.D (Kyoto University).

