
It is now understood that the attention mechanism in large language models (LLMs) serves multiple functions. By analyzing attention, we gain insight into why LLMs succeed at in-context learning and chain-of-thought—and, consequently, why LLMs sometimes succeed at extrapolation. In this article, we aim to unpack this question by observing various types of attention mechanisms.
Basic Idea
Many LLMs adopt an architecture that alternates attention mechanisms and multilayer perceptrons (MLPs). Each layer contains multiple attention mechanisms, each of which is called an attention head.
The roles of attention include:
- Retrieval within the context
- Realization of rules and algorithms
Here, “context” refers to the prompt together with the generated output so far, and next-token prediction is performed on top of this. The attention mechanism retrieves the information needed for next-token prediction from the context.
Some attention heads implement specific rules, and when multiple such heads coordinate, more sophisticated algorithms can emerge. They play a role analogous to the heads of a Turing machine. As a result, an LLM functions like a general-purpose computational device capable of running a variety of programs, applying appropriate processing to inputs it has never seen before, and producing suitable outputs.
The roles of the MLP are:
- Storage and retrieval of knowledge (= a database)
- Program execution
Tasks executed by an LLM are not limited to simple computations; they often require knowledge. An LLM stores knowledge in the MLP and retrieves and uses it as needed. Mathematically, if we express the parameter matrix \(W\)using orthogonal vector components as
$$\displaystyle W = u_1 v_1^\top + u_2 v_2^\top + \ldots + u_r v_r^\top$$
then we see that multiplication with the vector \(v_i\)gives \(W v_i = u_i\). In other words, feeding \(v_i\)into the linear layer of the MLP yields \(u_i\). This plays a role akin to a key–value store whose data are \((v_1, u_1), \ldots, (v_r, u_r)\). After this key–value store is constructed during pretraining, it is frozen at inference time. That is, the linear layers of the MLP function like a static database that does not depend on the input. As an aside, updating via LoRA as \(W + u v^\top\)can be interpreted as inserting a new key–value pair (or editing an existing one).
In addition to serving as a database, the MLP is responsible for transforming states—i.e., executing concrete programs—based on the input information retrieved by attention heads and the internal knowledge retrieved from the database by the previous layer.
In short, an LLM combines a Turing-machine-like general-purpose computational device with a static, pretrained database.
From this, we can see both the limits and the possibilities of LLMs. For tasks requiring internal knowledge, the model cannot answer questions about knowledge that is not present in the static database. LLM hallucinations can be viewed as cases where the database returns a miss, yet the program proceeds to execute and output regardless. In this sense, extrapolation is not possible for knowledge. On the other hand, for tasks that can be solved by logical reasoning, the computational device can execute a program and produce appropriate outputs even for inputs never seen during training.
This capability of LLMs stands out in contrast to classical N-gram language models. Next-token prediction by an N-gram model is grounded in the statistical properties of recent inputs. For example, “curry” and “rice” often co-occur, so “rice” has a high probability after “curry and”—this is the style of inference. Beyond such statistical prediction, LLMs can perform next-token prediction based on rules like grammar and on logic.
So far, we have outlined the basic idea that runs throughout this article. Next, we will examine specific behaviors through one of the most fundamental attention heads: the syntactic head.
Syntactic Heads
Some attention heads in LLMs are known to follow grammatical structure. We call such heads syntactic heads. For example, it has been observed that BERT’s 10th head in layer 8 attends from direct objects to verbs, and the 11th head in layer 8 attends from modifiers to nouns [Clark+ 2019]. Tokens that are not direct objects, or are not modifiers, attend to the [SEP] token under these heads. (Strictly speaking, it is debatable whether BERT should be called an LLM, but for the purposes of this article we include BERT.)

This model is trained entirely without explicit supervision (i.e., self-supervised learning), and no knowledge of grammar is provided explicitly. Nevertheless, as a result of unsupervised learning, such attention patterns emerge naturally. This suggests that these grammatical rules are intrinsic to token prediction and that basing prediction on grammatical rules enables token prediction to be more efficient and more accurate. There are of course many other ways to predict tokens, but the model, through free exploration, discovers that this approach is the most effective and thus comes to form these attention patterns.
It has been observed that syntactic heads are important for LLM capability. Early in training, attention is random and syntactic heads are absent. At a certain point, syntactic heads suddenly emerge, and immediately afterward the model’s grammatical competence increases sharply [Chen+ ICLR 2024].
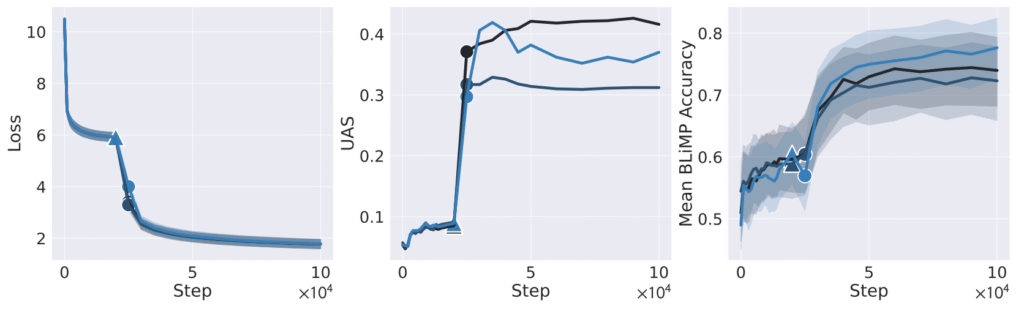
The degree to which a head aligns with grammar is computed by extracting, for each token, the token it most strongly attends to and then measuring the proportion that follows the parse tree. From the center graph above, we can see that this proportion increases sharply in the middle of training. Immediately after this, the tendency to prefer grammatically correct sentences rises steeply. This metric is computed using the BLiMP grammar dataset. BLiMP consists of pairs such as
- The cats annoy Tim.
- The cats annoys Tim.
that are almost identical except that one is grammatical and the other is ungrammatical. Each is fed to the model, and we compute which has higher likelihood (i.e., which is more readily generated). The right-hand graph shows the proportion of cases where the grammatical sentence is more likely. As these results show, once syntactic heads appear, the model becomes able to generate sentences that follow grammatical rules. Even before this timing, the training loss itself decreases, so the model should already be able to perform some level of token prediction; however, this is considered a statistical prediction that does not rely on grammar and instead exploits co-occurrence patterns. At this stage the model may still produce plausible sentences, but they may be ungrammatical or logically inconsistent. Only after syntactic heads emerge does the model reliably generate sentences that follow grammatical rules. Once such rules are acquired, when a sentence never seen during training is given as input, the model may not be perfect, but it is expected to process it appropriately by making reasonable, grammar-consistent inferences.
Up to this point, we have introduced the most fundamental syntactic heads and their significance.
We noted that syntactic heads cause tokens that are not direct objects, or are not modifiers, to attend to the [SEP] token under these heads. It is known that attention “sinks” like the [SEP] token can play special roles. To deepen our understanding of the role of attention mechanisms, we next take a closer look at such attention sinks.
Attention Sinks and Register Tokens
LLMs have been observed to direct strong attention to the first few tokens of the input text, to special tokens such as [SEP], and to punctuation and other symbols. Tokens that receive attention from many other tokens in this way are called attention sinks.
One role of attention sinks is to indicate that, under the rule in question, there is no corresponding target—just as syntactic heads use them as discard destinations for tokens that are irrelevant to the syntactic rule.
In autoregressive language models, the first token tends to become a sink because such models can only attend in the forward direction and therefore require a sink near the beginning.
In addition, attention sinks can store global information uniquely or serve as buffers for exchanging information with other tokens. Special tokens and punctuation carry little meaning by themselves. There is little need to encode token-intrinsic information in their internal states, leaving spare capacity. The model efficiently repurposes this free space to store information other than that of the token itself—particularly global information about the entire input.
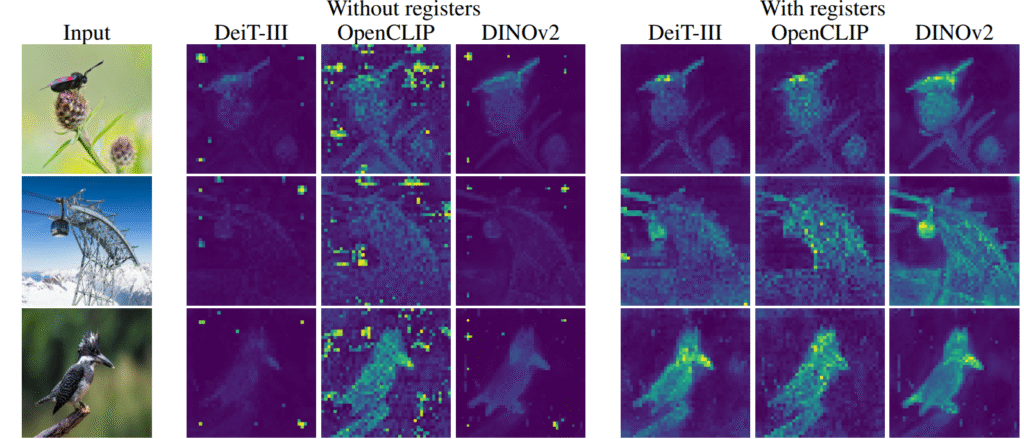
Attention sinks are observed not only in language models but also in vision transformers [Darcet+ ICLR 2024].

In vision transformers, uninformative background regions are used as attention sinks.
Darcet et al. further examined the internal states of these attention sinks and showed that the sinks’ internal states do not retain information about the original token, but instead retain information about the entire image [Darcet+ ICLR 2024]. Specifically, when solving a task that reconstructs a token’s position or pixel values from the token’s internal state alone, sinks perform worse than ordinary tokens—indicating that sink states do not preserve token-specific information. By contrast, when solving a task that predicts the class of the entire image from the token’s internal state alone, sinks perform better than ordinary tokens—indicating that sink states retain global information about the image.
This supports the hypothesis that tokens in uninformative background regions have spare capacity because they lack local information, and the model efficiently exploits this free space to store global information about the whole input. The model was not directly trained to use them this way; rather, through free exploration it discovered that this approach is effective and formed the corresponding attention patterns.
Building on this observation, Darcet et al. proposed adding a few meaningless tokens—register tokens—in addition to the input tokens [Darcet+ ICLR 2024].
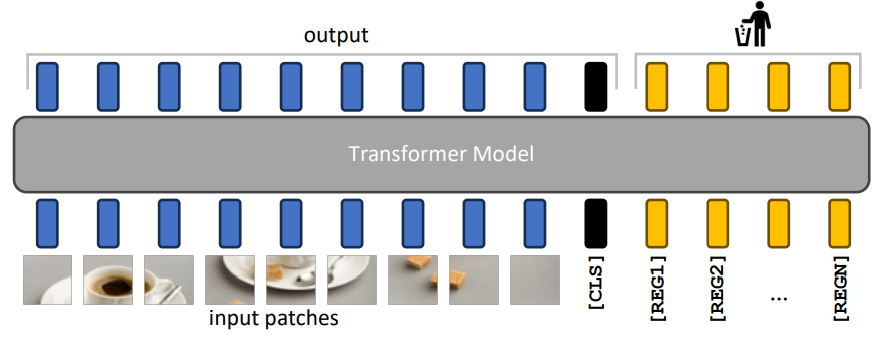
Because register tokens are even more meaningless than uninformative background regions, the model is expected to repurpose them as registers for storing global information. Recycling background regions as sinks is economical, but even background regions contain some information; using them as sinks risks information loss due to overcrowding. By providing dedicated register tokens as sinks, this information loss can be avoided.
With register tokens, performance improvements have been observed on several tasks. An additional benefit is that the model no longer directs sharp, strong attention to uninformative background regions, making the attention distribution “cleaner” and easier to interpret.
Register tokens have been observed to be effective in language models, especially in encoder-type models [Burtsev+ 2020]. Decoder-type—that is, autoregressive—models can only attend in the forward direction; while they can read the internal states of register tokens placed earlier, they cannot write to them, and thus cannot exploit them as registers. For this reason, register tokens are primarily used in encoder-type models with bidirectional attention mechanisms.
So far we have introduced these special attention targets—sinks. Many attention heads in LLMs attend only to the most recent tokens and to sinks, while some heads determine their targets programmatically across the entire context based on specific rules. Next, we observe the behavior of attention heads more broadly along the local versus global axis.
Streaming Heads and Retrieval Heads
A streaming head is a head that attends only to the most recent tokens and to sinks, whereas a retrieval head is an attention head that searches and retrieves information from the entire context [Wu+ ICLR 2025, Xiao+ ICLR 2025, Tang+ ICLR 2025]. It has been observed that LLMs generally have many streaming heads and a small number of retrieval heads.
As noted earlier, autoregressive language models are thought to use sinks not as registers but simply as discard destinations when there is no corresponding target under a given rule. Hence, streaming heads basically rely only on information from the most recent tokens and are considered to correspond to behavior grounded in the statistical properties of recent inputs, as in N-gram models. By analogy, streaming heads play the role of speaking fluently without thinking deeply.
By contrast, retrieval heads search over the entire context. It is also the role of retrieval heads to obtain from the prompt or prior utterances the premises needed to answer the current question and to maintain long-term coherence. By analogy, retrieval heads play the role of speaking carefully based on rules and logic.
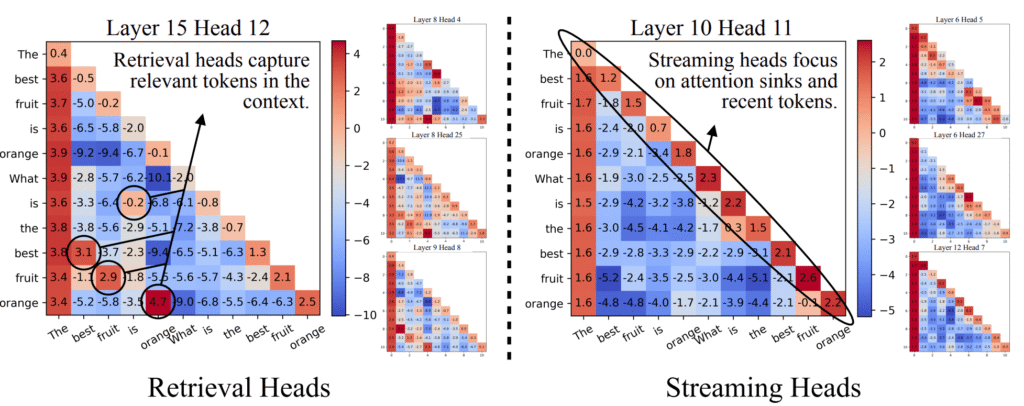
Retrieval heads have been observed to be extremely important for in-context learning. In the Needle-in-a-Haystack task, which requires obtaining information from the input context, removing 20 streaming heads caused almost no drop in performance, whereas removing 20 retrieval heads caused accuracy to drop from 94.7% → 63.6% [Wu+ ICLR 2025]. This suggests that a small number of retrieval heads are responsible for search within LLMs.
Next, we introduce induction heads—representative retrieval heads—and their internal mechanisms, moving toward the core of LLM capability.
Induction Heads
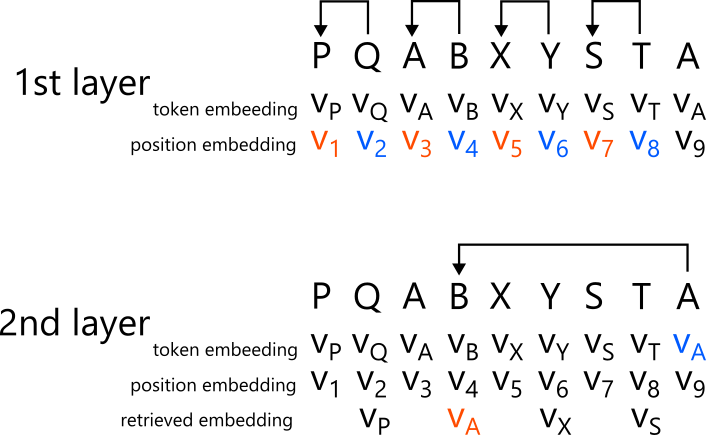
An induction head is a head that, for inputs of the form ... [A] [B] .... [A], attends from the latest token [A] to [B] [Olsson+ 2022]. In other words, it consults what happened next the last time the same token occurred. For example, given the following token sequence:
| Position | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| Token | P | Q | A | B | X | Y | S | T | A |
the induction head attends from the 9th token A to the 4th token B.
Induction heads realize in-context learning.
In-context learning is a method in which several input–output examples are provided in the prompt to support solving the actual target problem. For instance, for a movie-review sentiment analysis task, instead of presenting only the review to be classified, we prepend manually labeled examples that indicate what label should be assigned in which case, and have the LLM generate the continuation after the colon for the primary review.
It was so interesting that the ending arrived in a flash!: Positive
It was so boring that watching the dust dancing in front of the projector was more entertaining.: Negative
I was so absorbed I forgot to eat my popcorn, so I ate it at home!: Positive
Please stop starting a new part after the end credits.: Negative
It was a very interesting, excellent movie!:In this example, we want to label “It was a very interesting, excellent movie!”, but rather than presenting only that single example, we prepend labels for other examples to show what label to apply in which case, and then have the LLM generate the continuation after the colon for the primary data.
As the simplest distilled example of in-context learning:
grape: A
apple: A
car: B
egg: B
apple:In this case, the induction head attends to A, which is the next token after the previous occurrence of apple:, and as a result the LLM outputs A for the test apple:.
This is an idealized situation where there is an example in the input that exactly matches the test, and in such cases induction heads can predict the label accurately.
Induction heads are realized with two layers. A head in the first layer uses positional embeddings to attend to the immediately previous token; that is, it selects an attention target based on positional similarity to itself. It then applies an appropriate linear transformation to the value vector of the attention target and incorporates it into its own internal state. The second layer uses the token embedding thus incorporated to select attention targets based on whether the immediately previous token is similar to itself, and it attends to the target of the induction head. This can be achieved by transforming one’s own embedding in a direction consistent with the linear transformation of the value vector in the first layer before computing the attention target.
The approach of identifying mechanisms or algorithms embedded within a machine learning model to gain understanding of the model is called mechanistic interpretability. This article can be viewed as a tutorial on mechanistic interpretability of LLMs, with attention mechanisms as the central axis.
Thus far we have considered an idealized situation, but we also refer to as induction heads those heads that, for inputs of the form ... [A'] [B'] .... [A], attend from [A] to [B’]. Here, [A’] is a token or token sequence similar to [A].
In the movie-review example above, “It was a very interesting, excellent movie!:” corresponds to [A], “It was so interesting that the ending arrived in a flash!:” corresponds to [A’], and “Positive” corresponds to [B’].
Induction heads search for similar past examples and retrieve their subsequent tokens. That is, they refer to what happened next in similar past situations and use it for the current next token. As a result, the LLM comes to execute a nearest-neighbor-like prediction algorithm on the examples in the prompt.
Through in-context learning via induction heads, an LLM can be used as a general platform for executing nearest-neighbor methods. In this sense, extrapolation becomes possible.
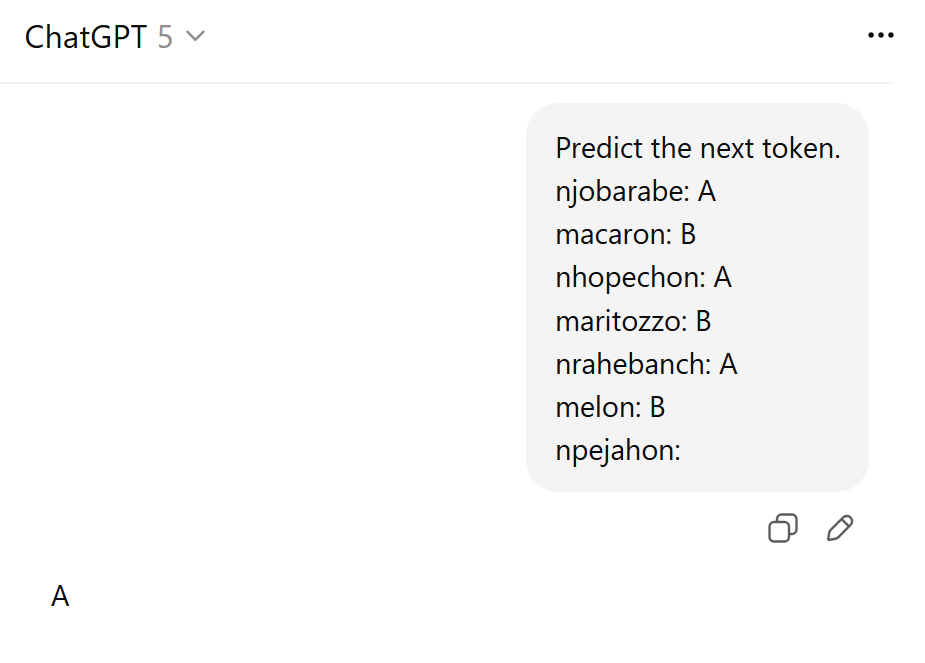
The figure above shows an example of classifying the mysterious word npejahon into A or B. The LLM should have never seen such a problem during pretraining. It should not even have seen the word npejahon, nor should it have classified words similar to npejahon into A or B. Even so, the LLM correctly classified npejahon as A. This is, in a sense, extrapolation.
Whether we call this extrapolation depends on perspective. The specific example npejahon, and specific examples similar to it, will not have been seen by the LLM at all—so in this sense it is extrapolation. On the other hand, the model must have repeatedly encountered during pretraining that executing a nearest-neighbor method or a similar algorithm often leads to good predictions; as a result, it came to realize a nearest-neighbor-like algorithm via induction heads, and indeed succeeded in the present prediction by doing so. In other words, at the surface token level it is extrapolation, but at the mechanistic/algorithmic meta level it is interpolation. However, once we start considering the meta level, any solvable problem can be labeled interpolation with a bit of hand-waving, making the decision of whether a problem is interpolation or extrapolation largely meaningless—a matter of viewpoint.
Up to this point, we have explained induction heads—the most basic attention heads that realize in-context learning via nearest-neighbor methods. However, what in-context learning enables is not limited to nearest-neighbor methods. Next, we turn to function vectors, which generalize this behavior.
Function Vectors
A function vector is a vector that represents a function for solving a task [Todd+ ICLR 2024].
In-context learning can also handle tasks that are not solvable by nearest-neighbor methods. For example,
short: long
common: rare
small:is a task that converts words to their antonyms, and
amount: cantidad
win: ganar
dreams:is a task that converts English to Spanish. In such cases, an algorithm that simply finds a similar example and copies its result will not suffice.
A function vector is, for example, a vector that represents the function that maps a word to its antonym, or the function that translates English to Spanish.
An LLM constructs, from the context, a function corresponding to the current task, passes that function together with the current input to the MLP to execute the program, and predicts the next token.
Todd et al. empirically verified that such a mechanism exists in LLMs and that functions are represented as vectors [Todd+ ICLR 2024].

First, for an antonym task, feed several in-context-learning prompts. Extract the internal state of the last token of each prompt and take their average. This becomes the function vector that implements the antonym task. That this vector functions as an antonym function vector can be seen by providing no examples at all—input only token: to the LLM—and then adding the function vector to the internal state at that time (i.e., to the MLP input), which leads the model to solve the task. For instance, we input only simple:. Without any additional information, many continuations would be possible, but adding the function vector to the MLP input triggers the antonym-computing circuit and the antonym is output.
Such behavior is observed not only for the antonym task but also for:
- Converting lowercase to uppercase
- Mapping country names to capital cities
- Translating English to French
- Converting present tense to past tense
- Converting singular to plural
In addition, a “+1” task can be realized with function vectors, e.g.,
Monday: Tuesday
December: January
a: b
seven:In all of these, the model is the same—hence the MLP is the same—and the MLP appears to act as a general converter, or a kind of higher-order function, that receives various function vectors and executes those functions.
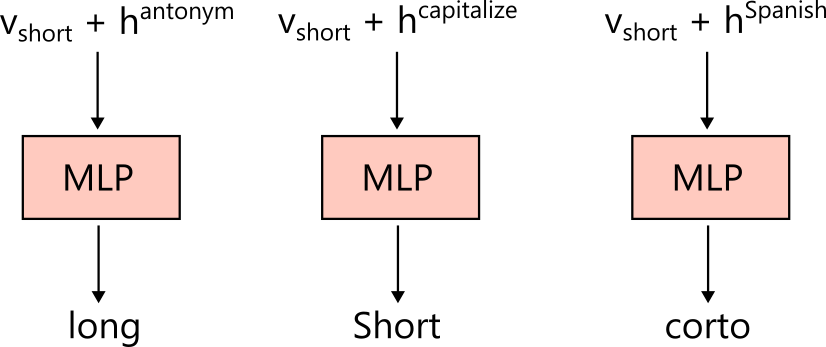
Once obtained, this function vector also works outside in-context learning. For example, input The word "fast" means to the LLM and predict the token after means. If we add the antonym function vector to the MLP input, the prediction becomes The word "fast" means slow. This suggests that the circuit that computes antonyms has been triggered and outputs the antonymic meaning.
Further,
short: Short
common: Common
small:can be used to derive a capitalization function vector; if we add this capitalization function vector to the MLP input for The word "fast" means, the next token begins with a capital letter.
These vectors may evoke the classic analogy in word vectors such as king − man + woman = queen. That understanding is broadly correct, but function vectors do not necessarily take only this linear form. For example, an antonym function vector \(h^{\text{antonym}}\) cannot satisfy such a linear relation. If adding the antonym function vector \(h^{\text{antonym}}\) effected the antonym transform, then from \(v_{\text{big}} + h^{\text{antonym}} = v_{\text{small}}\) and \(v_{\text{small}} + h^{\text{antonym}} = v_{\text{big}}\) we would obtain \(h^{\text{antonym}} = 0\). Therefore, the antonym function cannot be realized by simple vector addition; it is instead implemented by nonlinear transformations inside the MLP.
The implementation details differ depending on whether a task is knowledge-dependent. Functions for antonyms or Spanish translation are knowledge-dependent and are thought to be realized by leveraging the database within the MLP as appropriate. Consequently, antonyms not present in the database will not be transformed well—in other words, extrapolation is not expected. By contrast, converting lowercase to uppercase is purely procedural, so function execution can be expected to extrapolate to some extent. Tasks like converting present to past tense or singular to plural lie in between: for basic rules such as adding “ed” or adding “s,” some degree of extrapolation can be expected.
So far, we have examined how LLMs perform various kinds of in-context learning. Next, we turn to the attention heads that realize chain-of-thought, another key capability of LLMs.
Iteration Heads
An iteration head is a head that, in iterative computation, attends to the input position currently being processed [Cabannes + NeurIPS 2024]. Iteration heads are important for Chain of Thought.
Consider the problem of receiving a 01-string \(x\) and predicting whether the number of 1s is even or odd. For example, 0010101001: contains an even number of 1s, so the answer is 0 (even), whereas 1010101001: contains an odd number of 1s, so the answer is 1 (odd).
Let us solve this with Chain of Thought. Let \(s_i\) denote the parity of the first \(\i) characters. Then we can compute it via the following recurrence (the chain of thought):
$$\displaystyle s_0 = 0 \\ s_{i} = s_{i-1} + x_i ~(\text{mod} 2)$$
As a string, this can be represented by concatenating \(x\) and \(s\), e.g., 0010101001:0011001110 or 1010101001:1100110001. The final character corresponds to the parity over all characters and therefore represents the answer to the input.
Cabannes et al. trained a transformer language model from scratch using only strings like 0010101001:0011001110, and made it solve the problem via next-token prediction [Cabannes+ NeurIPS 2024]. Given input 0010101001:, the model solves the task by next-token prediction as follows:
0010101001:00010101001:000010101001:0010010101001:00110010101001:001100010101001:0011000010101001:00110010010101001:001100110010101001:0011001110010101001:0011001110
This is the simplest and most pristine form of Chain of Thought. As a result, the language model could compute parity with high accuracy even for unseen 01-strings. An internal analysis revealed iteration heads manifesting clearly via the mechanism described below.
The Chain-of-Thought portion \(s_i\) plays a role analogous to the tape in a Turing machine. The iteration head reads a character from the input, the MLP computes the sum of the current state and the input, and this is written onto a new tape. In this way, the parity-computation algorithm is realized. Thanks to the existence of the tape, more complex algorithms can be implemented than what could be realized by attention heads or the MLP alone in isolation.
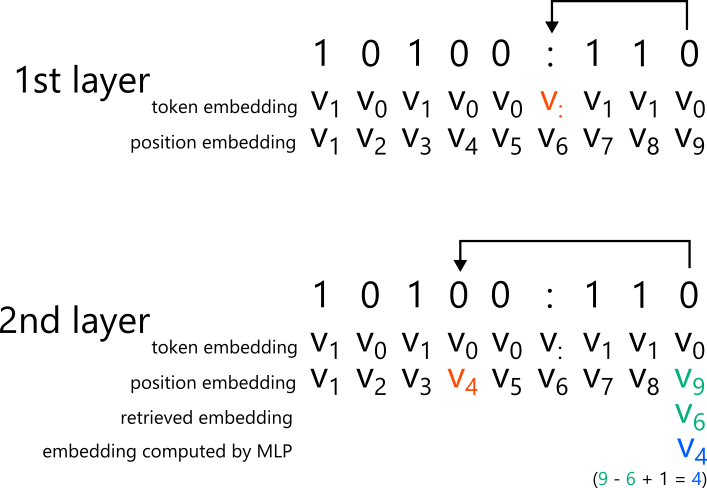
Iteration heads are realized with two layers. In the first layer, a head uses token embeddings to attend to the colon, i.e., the boundary between the input and the tape. It incorporates the positional embedding of the attention target as a value vector into its internal state. Next, the MLP computes ((its own positional embedding) – (the positional embedding just incorporated) + 1), thereby producing the positional embedding corresponding to the current input position. The second layer uses the computed positional embedding to attend to the iteration head’s target. Note that a single layer does not suffice for implementing an iteration head. With only the first layer, one knows only “which token index am I at” from the positional embedding. Even if one is at the 9th token, one cannot tell whether the input length is 6 and two tokens of the tape have been produced, or the input length is 5 and three tokens of the tape have been produced. By attending to the colon in the first layer and computing the distance from it, the model can determine how far processing has progressed.
Cabannes et al. confirmed—by observing the attention targets of the trained language model—that iteration heads are indeed realized in this manner.
In addition, similar iteration heads were found to emerge for tasks such as copying the input onto the tape and computing polynomial recurrences.
Real-world Chain of Thought is likely more complex than these tasks: pointers may move back and forth, and the tape may be consumed more heavily. Nevertheless, the essential operation is thought to rely on iteration heads and a tape-like mechanism of this form.
Summary
LLM attention mechanisms serve multiple functions, and by examining them we can clarify the mechanisms behind various LLM capabilities.
Sometimes on their own, and sometimes in concert with MLPs or with a Chain-of-Thought–style tape, LLM attention mechanisms implement rules, programs, and algorithms. LLMs operate as general-purpose computational devices for executing programs. In such cases, even for inputs entirely unseen during training, the model can sometimes generate appropriate answers by executing the relevant program—in other words, extrapolation is possible. Moreover, because an LLM is not merely a function evaluator but also contains, within its MLPs, a database accumulated through pretraining, it can realize functions that require knowledge—such as computing antonyms.
There are likely two main factors behind the acquisition of these abilities. First, the attention-based architecture naturally lends itself to implementing such programs. Second, once these abilities are acquired, the accuracy of next-token prediction improves qualitatively; through free exploration, the model discovers that this approach is most effective and proceeds to build the corresponding capability.
From this second perspective, it is likely that only algorithms that were useful during training are “programmed” into the model. Thus, while extrapolation may occur at the level of specific examples, at the meta level of rules or algorithms the behavior can be regarded as interpolation.
Even so, compared to classical models that could only make predictions from statistics at the level of concrete examples, this represents a qualitative shift. The ability to function as a general-purpose program executor is a major reason LLMs have become widely used and practical tools.
Of course, the internal operation of LLMs is not yet fully understood. There may be important attention heads beyond those introduced here, and even for the heads we discussed, alternative explanations or interpretations may exist.
I hope this article prompts you to reflect on LLM attention mechanisms and their capabilities.
Author Profile
If you found this article useful or interesting, I would be delighted if you could share your thoughts on social media.
New posts are announced on @joisino_en (Twitter), so please be sure to follow!

Ryoma Sato
Currently an Assistant Professor at the National Institute of Informatics, Japan.
Research Interest: Machine Learning and Data Mining.
Ph.D (Kyoto University).

